Statistics & Finance II
Taught by Sotirios Damouras.
PDF version here
W1: Financial Data & Returns
Continuous double auction
- Real-time mechanism to match buyers & sellers and determine prices at which trades execute
- At any time, participants can place orders in the form of bids (buy) and asks (sell)
- Matching orders (bid ask) are executed right away, whereas outstanding orders are maintained in an order book
Order types
- Limit order: transact at no more/less than a specific price
- If order not filled, it’s kept in the order book
- Market order: transact immediately at current market price
- A single order can have more than one price
- Iceberg order: contains both hidden and displayed liquidity
- Splits a large order into smaller ones to maintain order anonymity
Financial data
- Quote data: record of bid/ask prices from order book
- Trade data: record of filled orders
Daily data
- Open/close
- Adjusted close (used for calculating returns): adjusted for dividends and splits
- High/low
- Volume
Candlestick
- Green: close > open
- Red: close < open
Other data
- FX rates: currency prices set by global financial centers
- LIBOR rates: average interest rate that major London banks would be charged when borrowing from each other
Reliability of financial data
Financial data could be skewed by
- Fake orders: trades placed to manipulate prices w/o intention to trade
- Fake trades: trades where buyer and seller is the same party, used to increase trading activity
Returns
Log returns (assumes continuous compounding)
Dividend adjustment
Assuming dividend is reinvested, the adjusted return is
The dividend is added back to the price (after the price drop)
Split adjustment
Net vs log returns
for small values of (<1%)
Taylor approx.:
Monthly returns
For daily net returns , monthly net return is:
For daily log returns , monthly log return is:
Random walk model
Additive log returns suggest using the following to model asset prices
If are i.i.d., then the log return process is a RW with drift and volatility
- aggregate returns over periods has mean and volatility
Exponential/geometric random walk
Return distribution
- Most convenient assumption: normal (by CLT)
- Not a good description of reality due to fat tails (heavier than normal)
- Skewness =
- Right skewed positively skewed
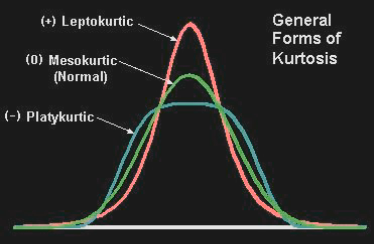
- Kurtosis =
-
Measures heaviness of the tails
-
Defined as the standardized fourth central moment of a distribution minus 3, which is the kurtosis of the standard normal distribution
-
Returns are leptokurtic
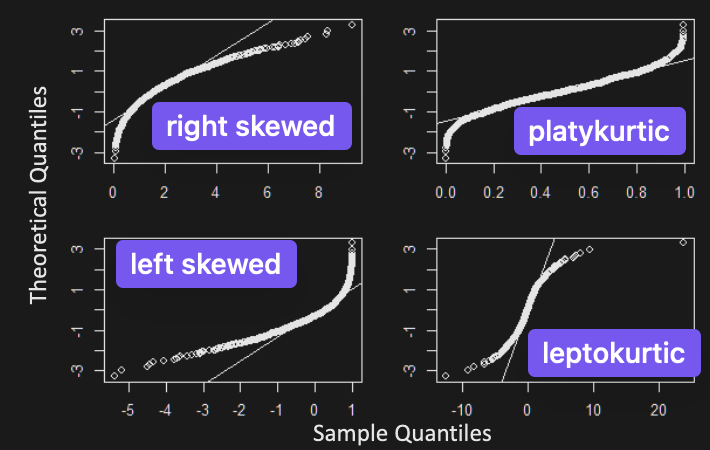
-
E.g. Identify skewness/kurtosis from QQ plot
W2: Univariate Return Modelling
Normality tests
- Kolmogorov-Smirnov - Based on distance of empirical & Normal CDF
- Jarque-Bera - Based on skewness & kurtosis combined
- Shapiro-Wilk (most powerful) - Based on sample & theoretical quantiles (QQ plot)
Heavy tail distributions
A pdf is said to have:
- Exponential tails, if
- Polynomial tails, if
Heavy tailed distributions are those with polynomial tails.
- is the tail index controlling tail weight: smaller heavier tails
- for , moments are infinite:
- Although the MGF’s is infinite, the characteristic function always exists (refer to PS2 Q2)
Examples
Pareto
Cauchy:
Student’s t:
Theoretical justification
Let i.i.d. heavy tail distributions with tail index
By the generalized CLT, the aggregate return stable distribution
A distribution is stable if linear combinations of independent RVs have the same distribution, up to location and scale parameters.
- All stable distributions besides the Normal have heavy tails, but not all heavy tailed distributions are stable (unstable if tail index > 2)
- Moreover, the sum of independent stable RVs also follows a stable distribution
- Thus, adding many heavy tail i.i.d. price changes, we get heavy tail returns
Modeling tail behaviour
The complementary CDF of a heavy tail distribution behaves as:
To model (absolute) returns above a cutoff , use Pareto distribution
To estimate tail index , use:
- Maximum Likelihood:
- Pareto QQ plots (for tails, e.g. top 25% of returns):
- Plot empirical CDF vs returns in log-log-scale
- Estimate using slope of best fitting line (simple linear regression)
- Student’s t QQ plot (for entire distribution, not just tails)
- Adjust for location and scale where
- Estimate parameters using MLE
- Mixture models
- Generate an RV from one out of a family of distributions, chosen at random according to another distribution (a.k.a. mixing distribution)
- Easy to generate, but not easy to work with analytically
- 2 types: discrete and continuous
- e.g. (discrete mixing distribution) RV generated from
- e.g. (discrete mixing distribution) RV generated from
- e.g. (continuous mixing distribution) where is a RV. This is called a normal scale mixture.
- Examples with heavy tails:
- (GARCH) where the mixing process for is
- (T-dist) where
- Examples with heavy tails:
- Generate an RV from one out of a family of distributions, chosen at random according to another distribution (a.k.a. mixing distribution)
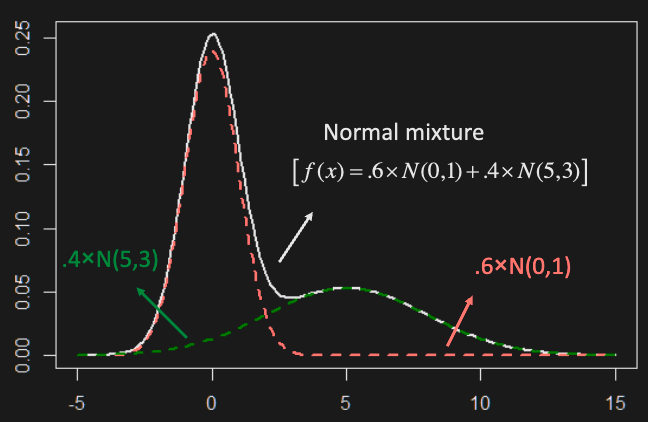
E.g. using mixture models, verify that for ,
Hint: if , then .
Stylized Facts
Typical empirical asset return characteristics:
- Absence of simple autocorrelations
- Volatility clustering
- Heavy tails
- Intermittency (alternation between periodic and chaotic behaviour)
- Aggregation changes distribution (the distribution is not the same at different time scales)
- Gain/loss asymmetry
Extreme value theorem
2 limit results for modelling extreme events that happen with small probability
1st EVT (Normalized max of an iid sequence converges to the generalized extreme value distribution)
Let be i.i.d. RVs and .
normalizing constants s.t.
If exists, it must be one of:
We can combine the three types into the generalized extreme value distribution
is the shape parameter:
- for heavy tails
- for exponential tails
- for light tails
E.g. Show that the “normalized” max of iid Uniform (0, 1) with , converges to Weibull for
2nd EVT (Conditional distribution converges to GPD above threshold)
For RV with CDF , consider its conditional distribution given that it exceeds some threshold :
where is the right endpoint (finite or ) of
In certain cases, as , the conditional distribution converges to the same (family of) distributions called the Generalized Pareto Distribution (GPD)
where , and for
This gives:
- : heavy tails (tail index )
- : exponential distribution
- : finite upper endpoint
W3: Multivariate Modeling
We can model the returns of a linear combination of assets using a constant matrix like so
To minimize the effect of outliers, we can use robust estimation - an estimation technique that is insensitive to small departures from the idealized assumptions that were used to optimize the algorithm
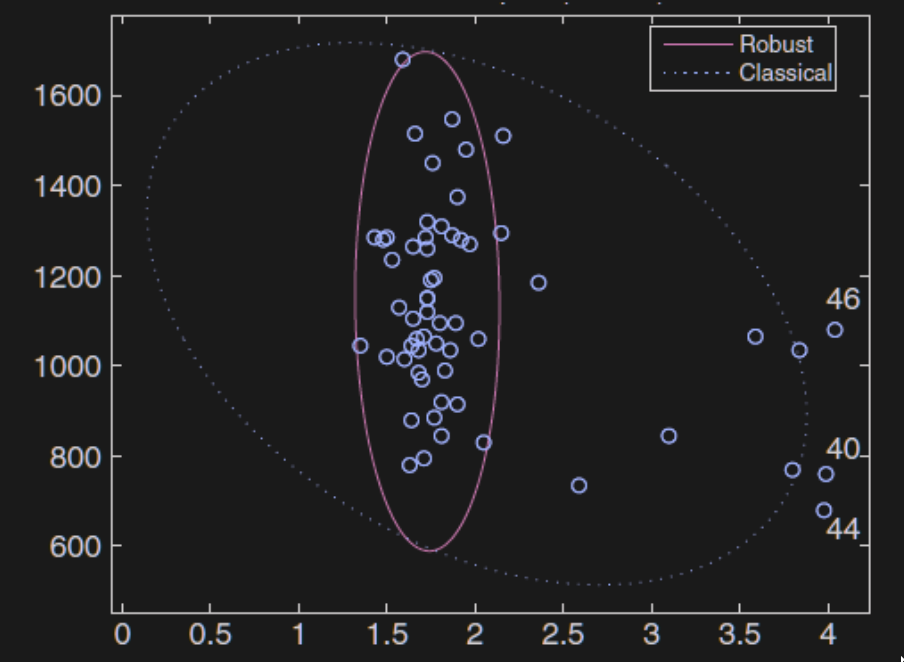
However, we should never remove outliers in finance. We can instead model heavy tails using the following.
Multivariate (Student’s) t distribution
A more practical/realistic distribution than Normal for modelling financial returns.
where
Note that it is a Normal that gets scaled/divided by the square root of a Chi-square
Notation: where , not
, but
Marginals are t-distributed with the same degrees of freedom all asset returns have the same tail index
There is tail dependence - extreme values are observed at the same time in all dimensions (desirable property for modelling financial returns)
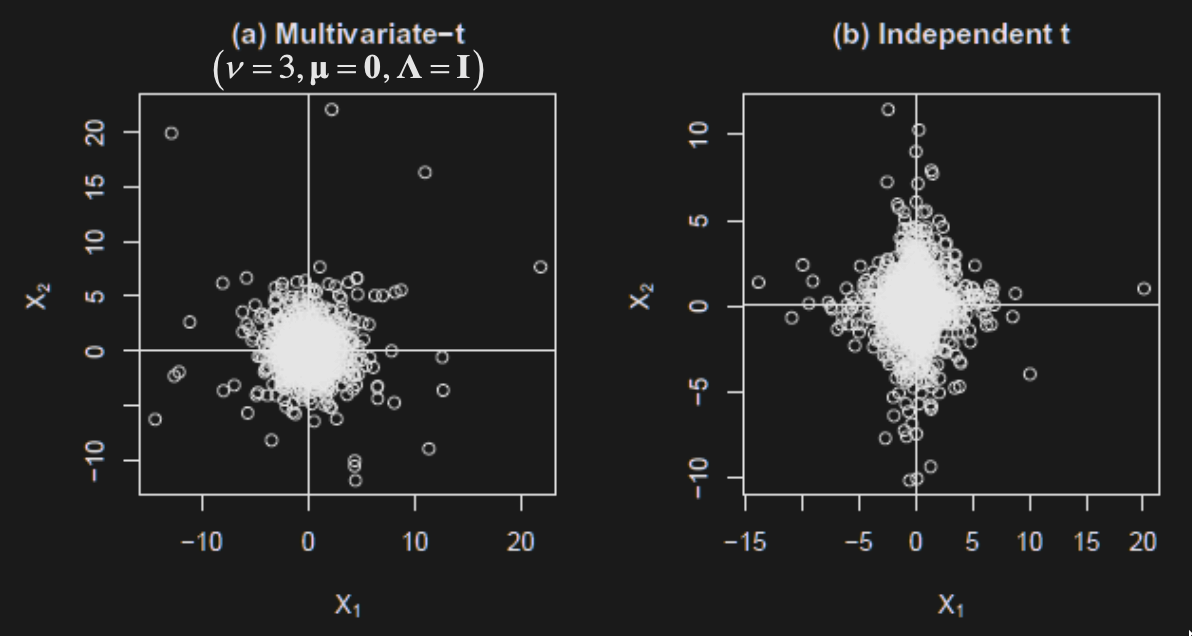
The greater the tail dependence, the more points we will observe in the corners (figure on the left has tail dependence).
Linear combinations of multivariate t follow 1D t with the same df
Using the same degree of freedom is limiting. A more flexible way is to model dependencies with copulas.
Copula
Intuitively, copulas allow us to decompose a joint probability distribution into the following:
- their marginals (which by definition have no correlation)
- a function which couples them together
thus allowing us to specify the correlation separately. The copula is that coupling function. (joint = copula + marginals)
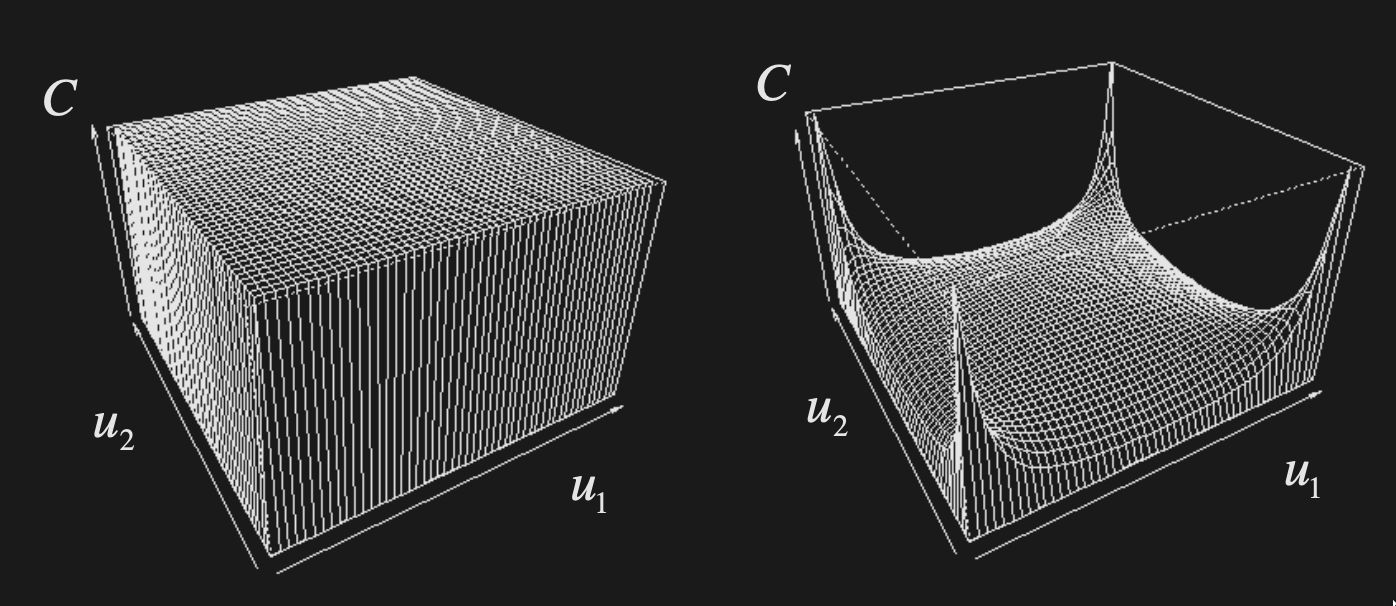
Formally, a copula is a multivariate CDF with Uniform(0, 1) marginals
Independence copula
Fréchet-Hoeffding theorem (Copula bounds)
Any copula is bounded like so
- The lower bound is 1 minus number of uniforms plus the values of the uniforms. Observe that the min of the copula is only non-zero if the average value of the uniforms
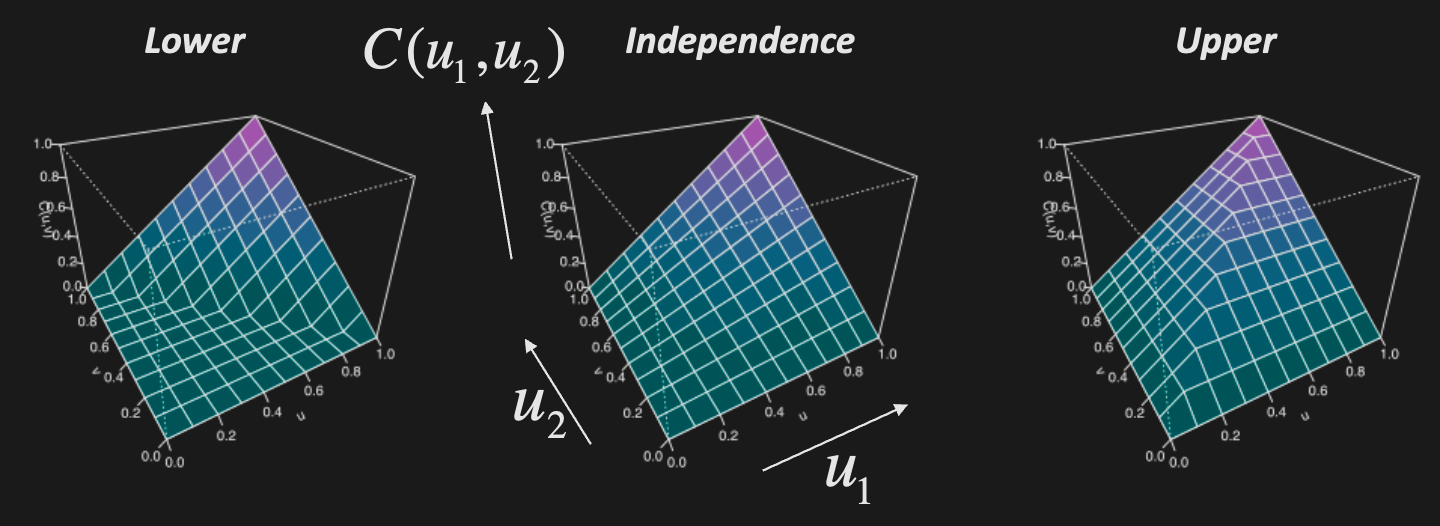
Sklar’s Theorem
Any continuous multivariate CDF with marginal CDF’s can be expressed as a copula
The inverse is also true: any copula combined with marginal CDFs gives a multivariate CDF
If we let
So, for continuous CDF with marginals , the copula is given by
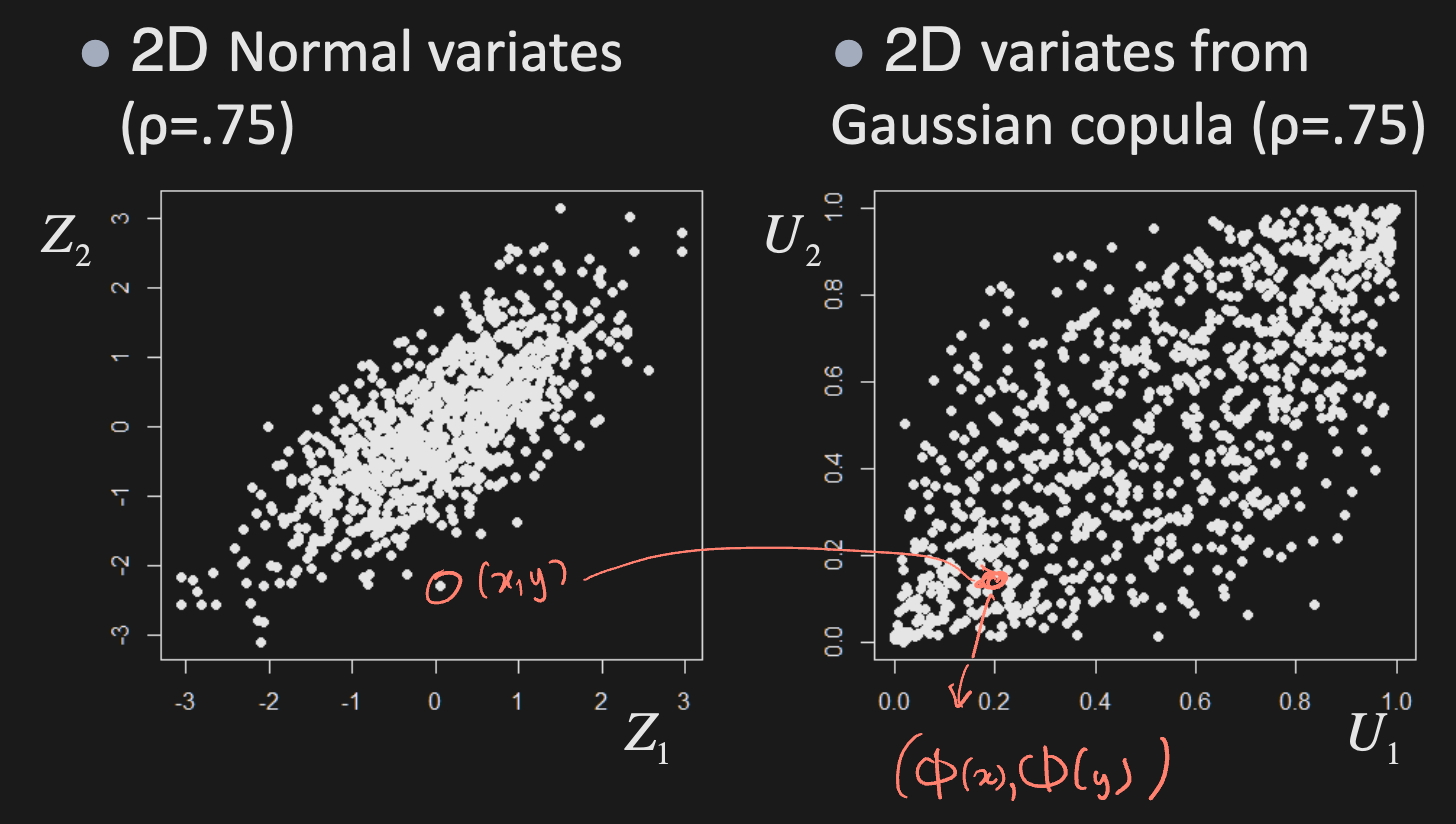
E.g. If , then , and
Gaussian Copula
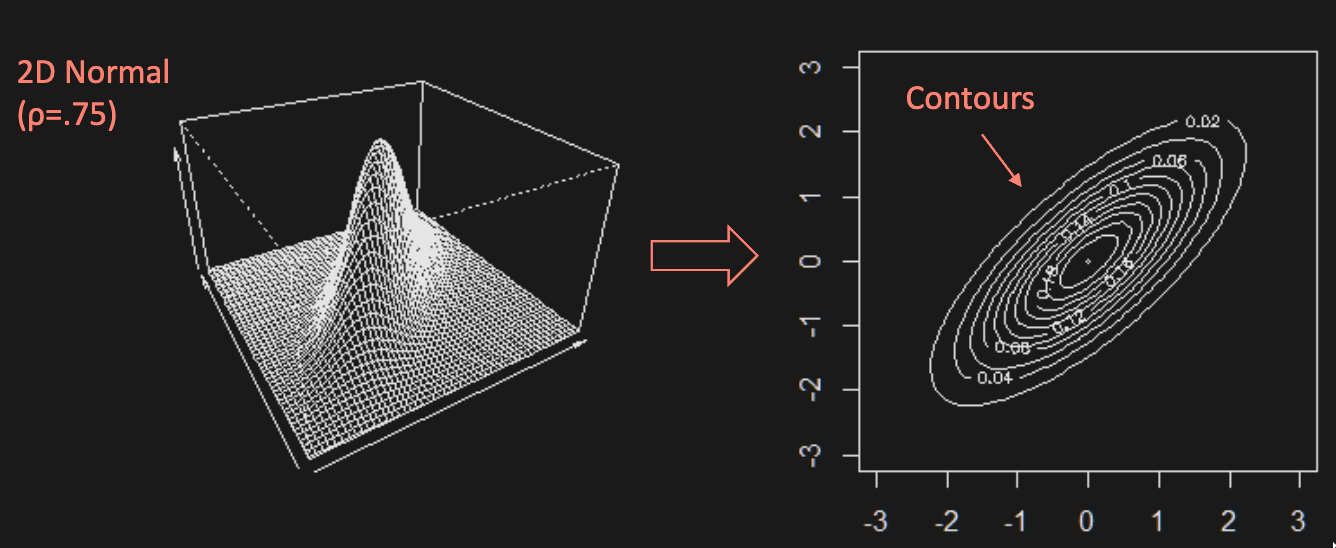
Suppose with correlation matrix . Its copula is given by
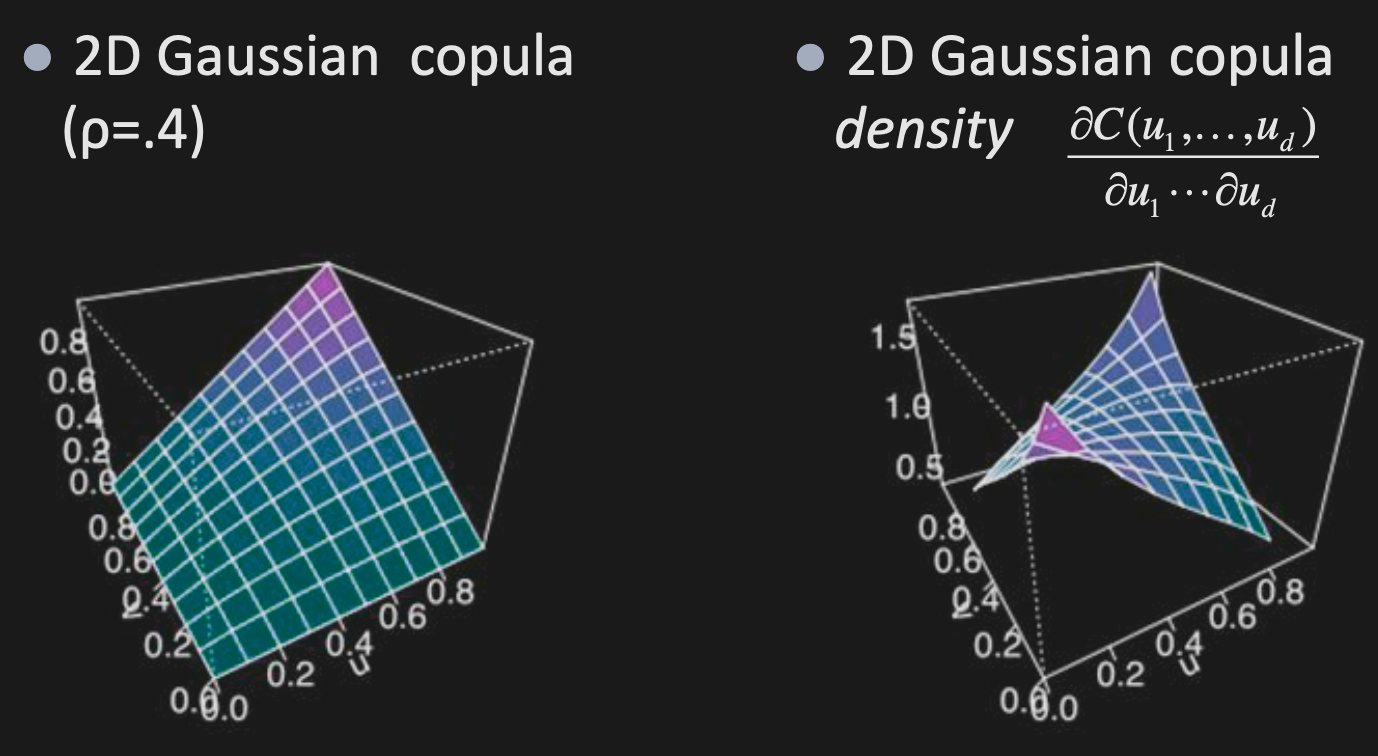
For the independent copula, the derivative would be a plane.
Note: The Gaussian copula only depends on , not on the individual means and variances (’s and ’s). Shown below.
Meta-Gaussian distributions
Multivariate distributions with a Gaussian copula
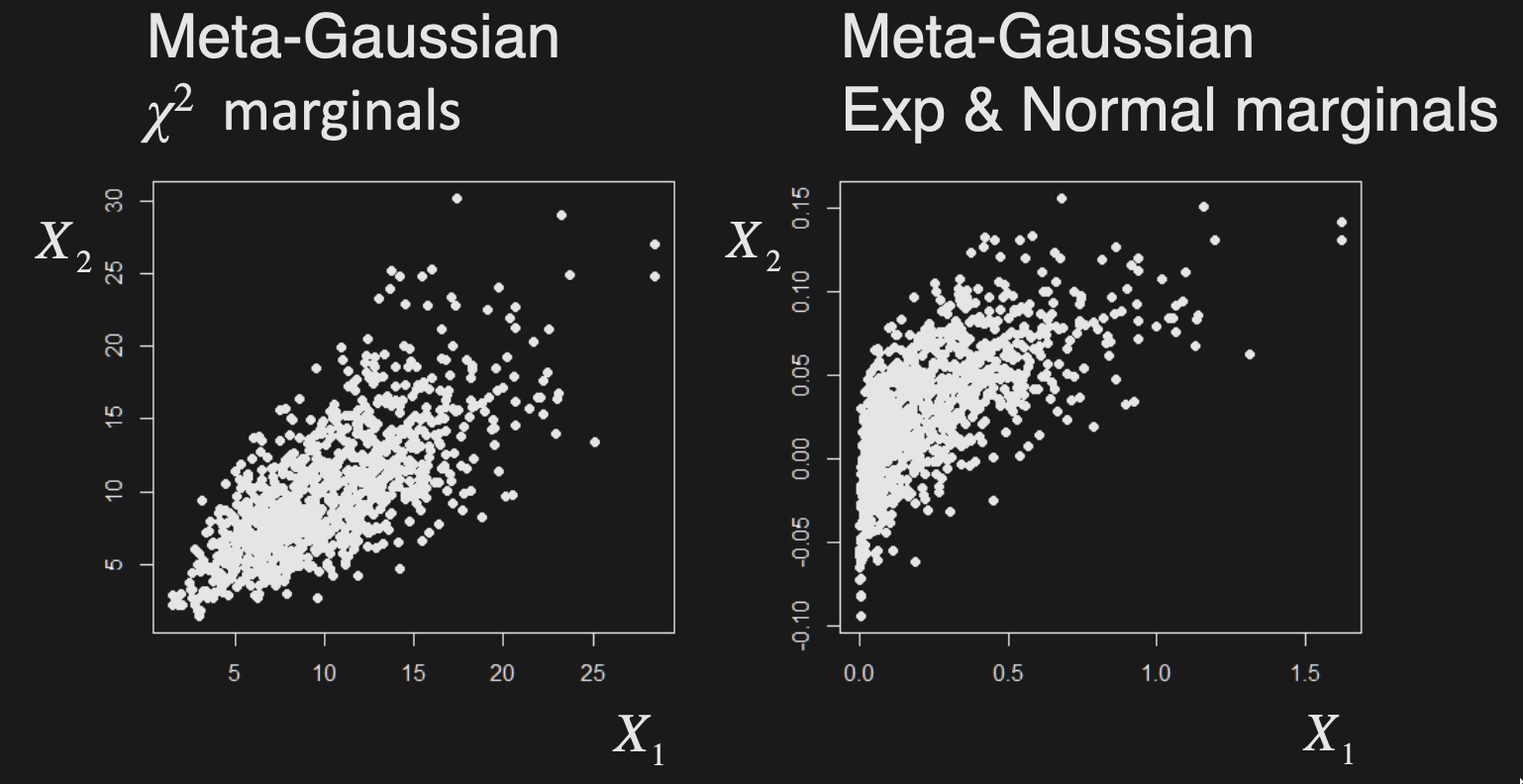
Simulation
Copulas can be created from known distributions. To simulate data from a distribution with copula and marginals :
- Generate (dependent) uniforms
- Generate target variates from marginals
E.g. To generate uniforms from Gaussian copula:
- Generate multivariate normals with correlation
- Calculate uniforms as their marginal CDF’s
- Then, use these uniforms with any other marginals
For , the pdf of a Gaussian copula vs a t copula looks like
Elliptical copula
Normal and t distributions both have a dependence structure that is said to be elliptical (due to their elliptical contours)
Symmetry of covariance matrix same dependence strength for positively and negatively correlated values
Archimedean copula
Family of copulas with the following form
where is called the generator function with the following properties:
- is continuous and convex
There are infinitely many choices for , but the most common ones are:
2D Archimedean copula random variates:
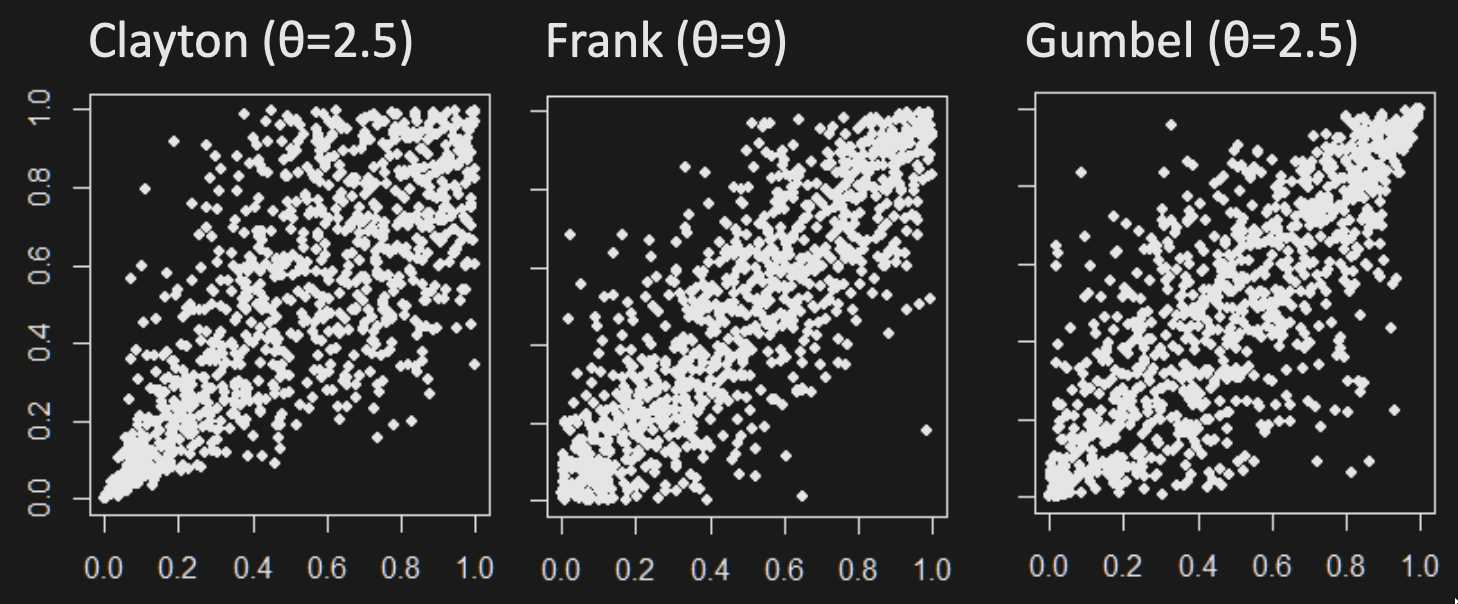
Contours of 2D pdf’s with Archimedean copulas and standard normal marginals:
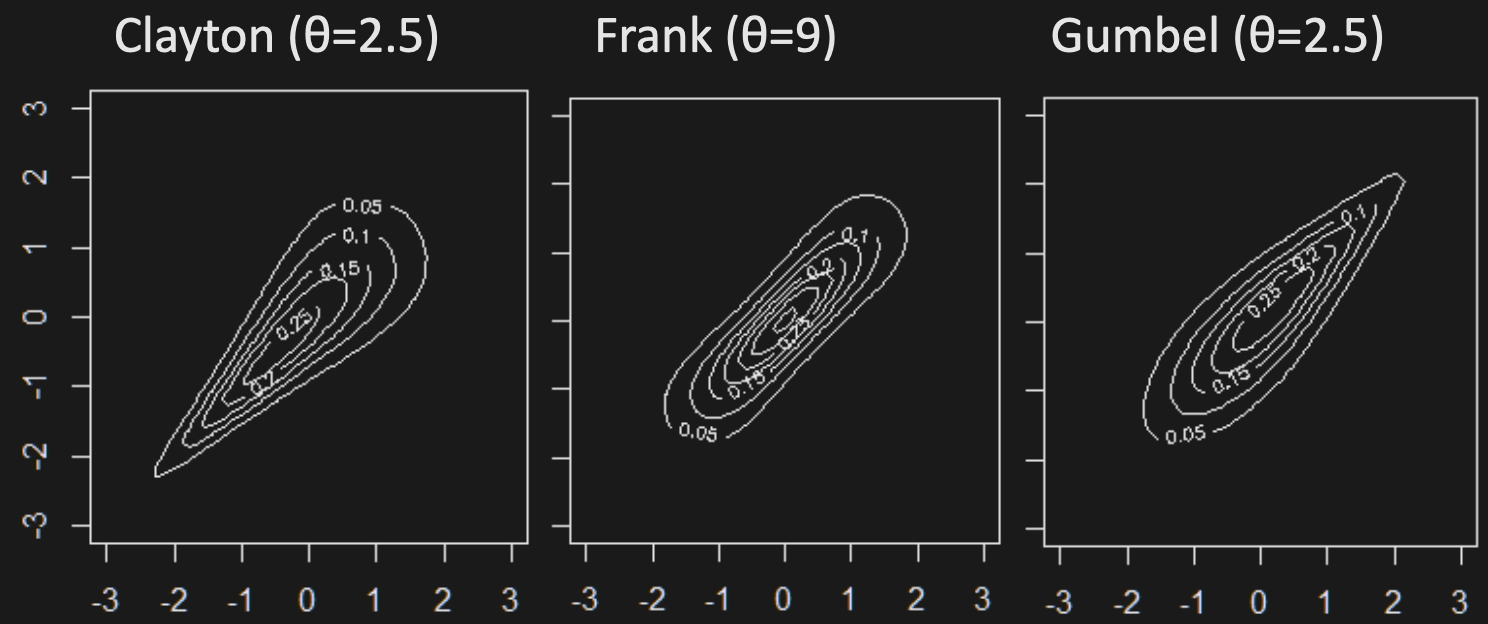
Although Archimedean copulas can model dependence asymmetries, there are limitations in 3D
- The copula value is constant for any permutation of coordinates
- All pairs of coordinates have the same dependence, which is not the case for elliptical copulas
Alternative: vine copulas, which allow for both asymmetry and differences in pairwise dependence.
Fitting copulas
For given copula and marginals, we can use MLE to fit multivariate distribution parameters to data, but the number of parameters can be very high.
Instead, use pseudo-MLE to break problem down into marginals and copula:
- Estimate marginal params for each dimension and calculate uniforms
- Then estimate copula using ML on uniforms
W4: Portfolio Theory
Assumptions:
- Static multivariate return distribution
- Investors have same views on mean & variance
- Investors want minimum risk for maximum return
- Investors measure risk by portfolio’s variance
- No borrowing or short-selling restrictions
- No transaction costs
Two asset portfolio
The portfolio return is
We can model it like so
where with
Let , , then
To minimize, differentiate w.r.t. w and set to 0:
Multiple asset portfolio
Consider n risky assets with returns
A portfolio with weights s.t. has
To find the min variance portfolio with given expected return , we solve the following quadratic optimization problem with linear constraints
The set of such portfolios forms a parabola in mean-variance space, containing attainable portfolios.
Minimum variance portfolio weights
We can use Lagrange multipliers to find the minimum variance portfolio weights:
Lagrange Multipliers are used to find the local max/min subject to equality constraints
1 constraint (2 variables): example
M constraints (n variables):
Objective function (Lagrangian):
Differentiate and set to 0:
Solve for lambda:
Plugging lambda into , we get
It is the row sums of divided by the sum of all its elements.
Risk-free asset
Consider splitting an investment into portfolio & risk-free asset, with weights and
A risk-free asset has constant return
The return is given by , with
For a set of assets including risk-free ones, the best investments lie on the line tangent to the efficient frontier - they are combinations of the tangency portfolio and risk free assets.
- The tangency portfolio is the efficient frontier portfolio that belongs to the tangent line.
- The slope of the line is the Sharpe ratio.
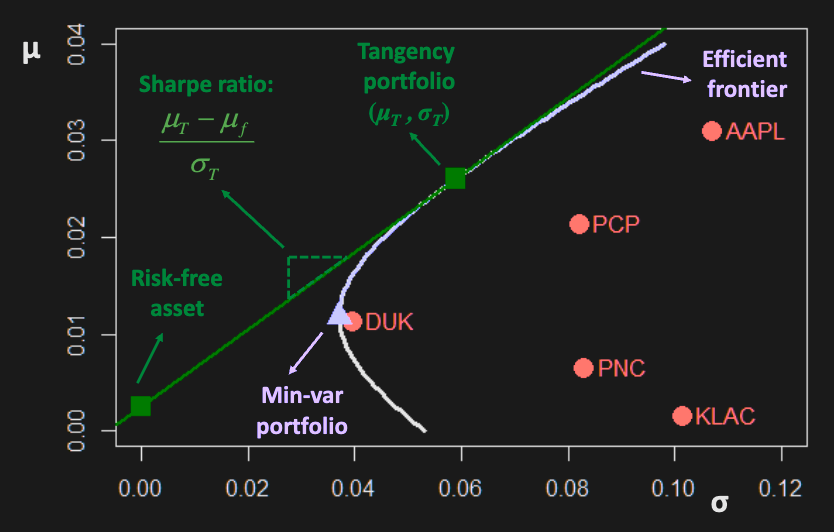
To find the tangency portfolio, maximize Sharpe ratio.
Tangency portfolio weights (solution to above) are given by
CAPM (Capital asset pricing model)
If every investor follows mean-variance analysis & the market is in equilibrium, then:
- Every investor holds some portion of the same tangency portfolio
- The entire financial market is composed of the same mix of
risky assets - Tangency portfolio is simply the market value-weighted index
Market portfolio
Since composition of the tangency portfolio is equivalent to that of the market portfolio, its weights are just
where = price of asset i, = # shares outstanding
Capital market line
Every mean-variance efficient portfolio lies on the capital market line:
where is the risk free rate, and is the market portfolio
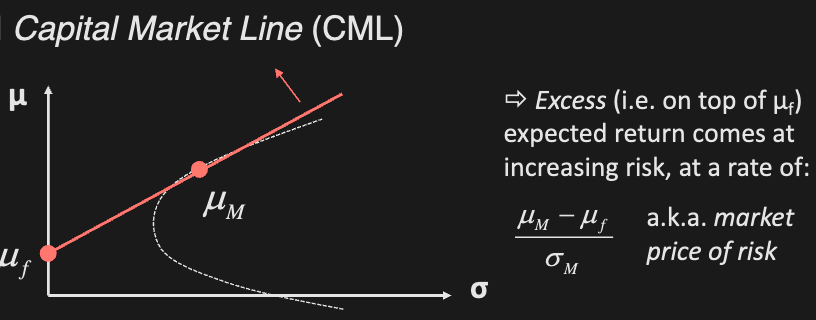
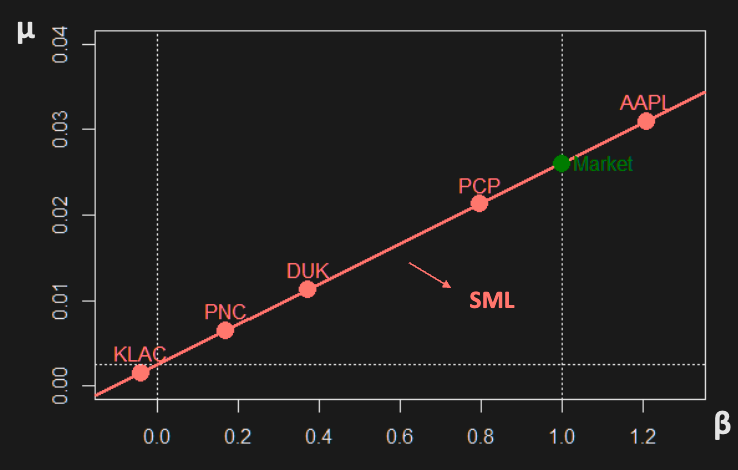
Security market Line
CAPM implies the following relationship between risk and expected return for all assets/portfolios (not just efficient ones)
Implications:
- At equilibrium, an asset’s return depends only on its relation to the market portfolio.
- measures the extent to which an asset’s return is related to the market. Higher higher risk and reward.
- Investors are only rewarded with higher returns for taking on market/systematic risk
Derivation: max Sharpe ratio using 1st order conditions
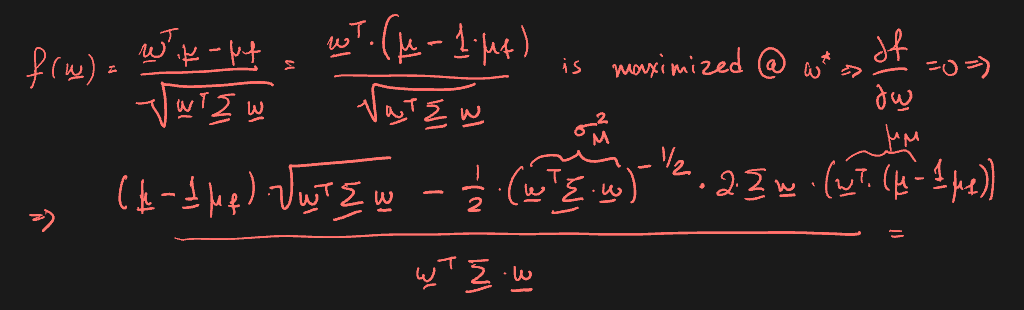
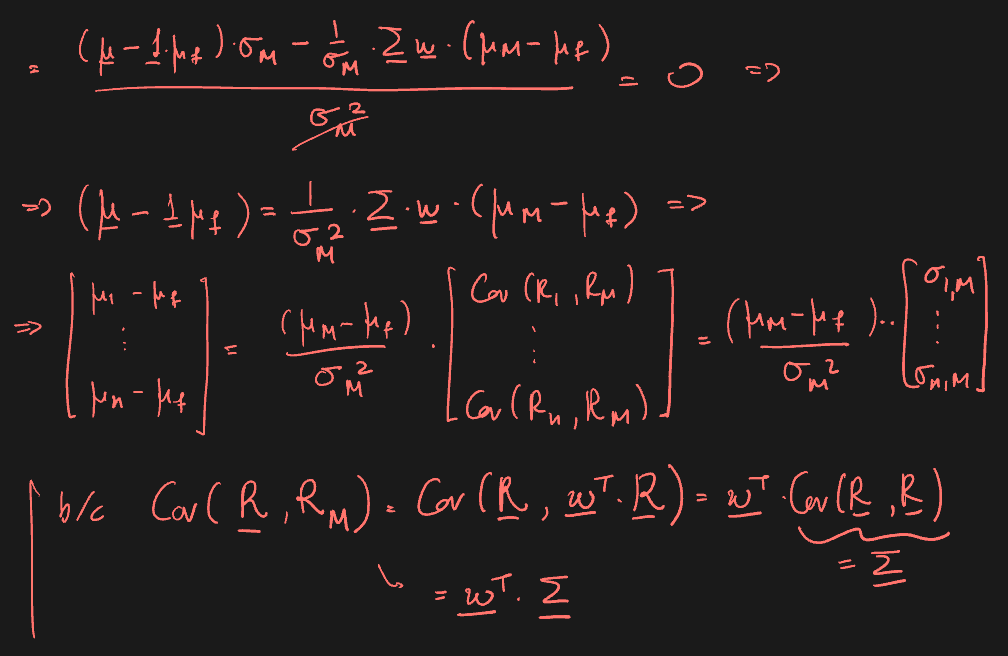
E.g. Consider N assets with iid returns and risk free return . Find market portfolio weights and SML.
,
Since the market portfolio is the min variance portfolio, we have
So the minimum variance is
Security characteristic line
To find ’s empirically, regress () on ()
- is the market return (proxy by large market index, ex S&P500)
- is the risk free rate (proxy by T-bill)
The slope of the SCL is the beta estimate:
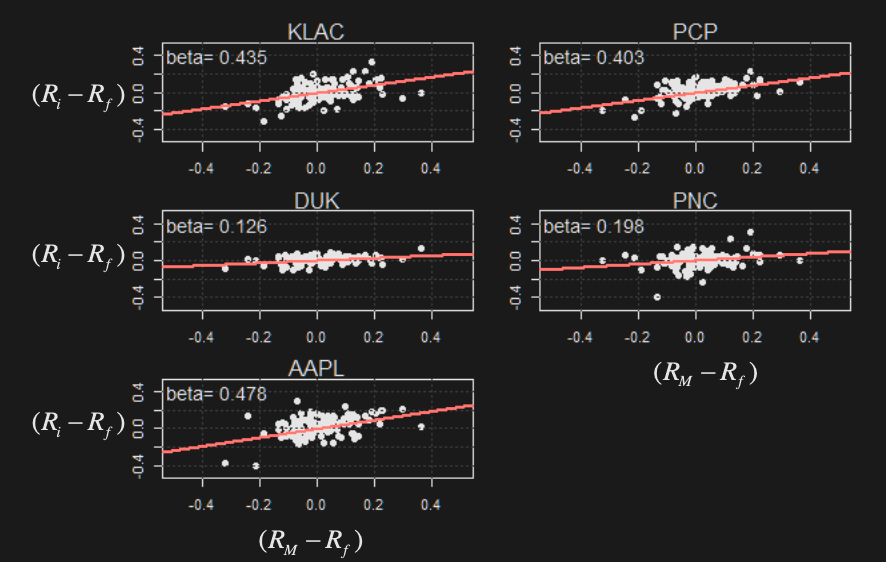
Mean return vs estimated betas:
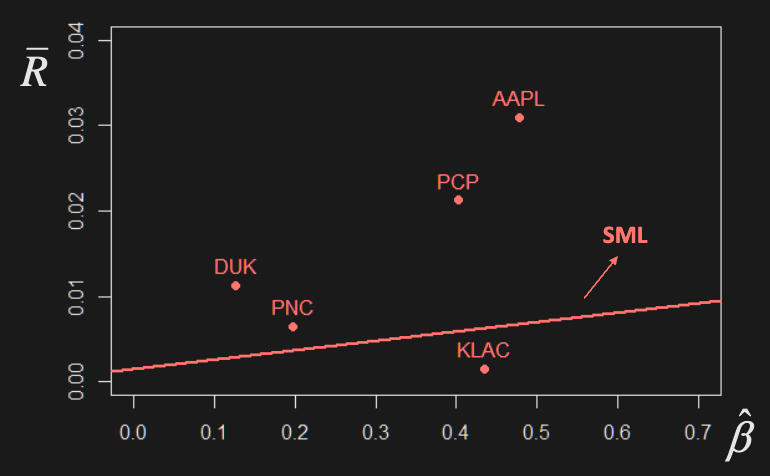
Now consider adding an intercept,
The mean and variance are given by
measures the excess increase in asset return on top of that explained by the . The bigger the alpha, the higher the outperformance (compared to the market portfolio).
Legacy of CAPM
CAPM says the best portfolio you can create is the tangency/market portfolio. This implies the best you can do is get the broadest index and combine it with a T-bill.
CAPM is wrong, but had immense practical impact on investing, specifically in terms of
-
Diversification: concept of decreasing risk by spreading portfolio over different assets
-
Index investing: justification for common investing strategy of tracking some broad index with mutual funds or ETF’s
-
Benchmarking: Measuring performance of investment relative to market / index
Performance Evaluation
There are several ways to measure an asset’s performance, based on CAPM
Sharpe ratio: (excess return per unit risk)
Treynor index: (excess return per unit non-diversifiable risk)
Jensen’s alpha: (excess return on top of the return explained by the market)
- Usually the most important measure a portfolio manager tries to use to convince people to invest in them.
W5: Factor Models
Main implication of CAPM: the market is the single factor driving asset returns
To improve performance, use more factors that drive asset returns
Factor Models
3 types:
- Macroeconomic: Factors are observable economic and financial time series
- Fundamental: Factors are created from observable asset characteristics
- Statistical: Factors are unobservable, and extracted from asset returns
All 3 types follow some form of
- is return on the asset at time t
- is the common factor at time t
- is the factor loading/beta of asset on the factor
- is the idiosyncratic/unique return of asset
In matrix form:
Assumptions:
- Asset specific errors are uncorrelated with common factors
- The factors are stationary, with moments
- Errors are serially and contemporaneously uncorrelated across assets
Find moments of model
Find moments of portfolio with , i.e.
Time Series Regression Models
Consider model for which factor values are known (e.g. macro/fundamental model).
We can estimate betas & risks (variances) for one asset at a time. For each , fit regression model:
over observations
Most models will always include some proxy for the overall economy (e.g. the market). The following is a famous example.
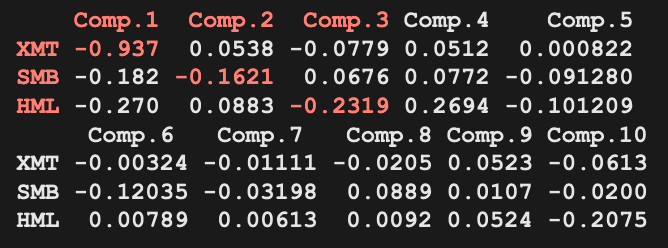
Fama-French 3 Factor Model
3 factors
- Excess Market Return (XMT)
- Same as in CAPM.
- Small Minus Big (SMB)
- Captures the size (market cap) of the company/stock.
- High Minus Low (HML)
- High = value stock; low = growth stock.
- Measured using book-to-market ratio.
We can use the factor model to estimate the return covariance matrix.
where:
This gives more stable estimates than sample covariance.
Statistical Factor Models
Factors are unknown and unobserved
- Need to estimate both and
- Problem is ill-posed need constraints
Assumptions
- Asset specific errors are uncorrelated with common factors
- The factors are orthogonal, with moments
- Errors are serially and contemporaneously uncorrelated across assets
Resulting moments of returns
Principal component analysis
PCA: constructing a set of variables (components) that capture most of the variability given a set of assets
It can be thought of as a linear transformation of original variables.
For a random vector with covariance (correlation ), the PC’s are linear combinations of
such that:
- are uncorrelated
- Each component has maximum variance
Problem definition
We want to find components (i.e. find coefficient vectors ) s.t.
- maximizes subject to
- , for any
Solution
Given by eigen-decomposition of
where
- P is an orthogonal matrix, i.e.
Principal components:
Find
Find the loading of on (the beta)
Total variance of all PC’s = variance of original variable
Proportion of total variance explained by each PC is
How do we choose the number of PCs?
-
We can use a scree plot:
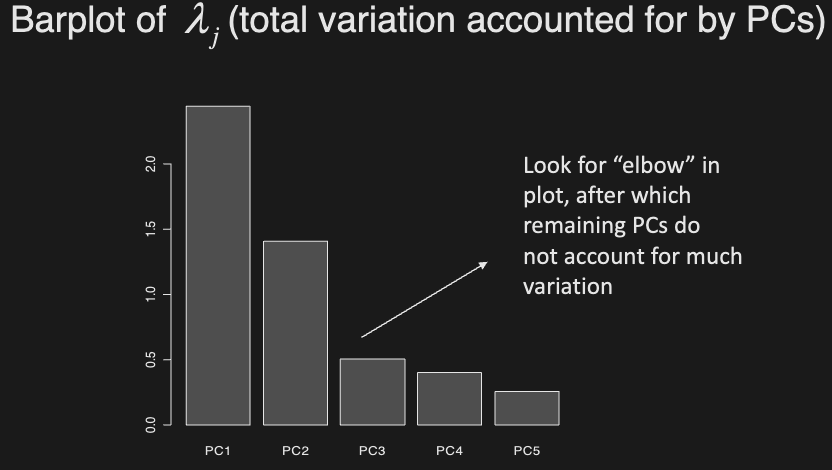
-
E.g. In this example, one PC already explains much of the variation
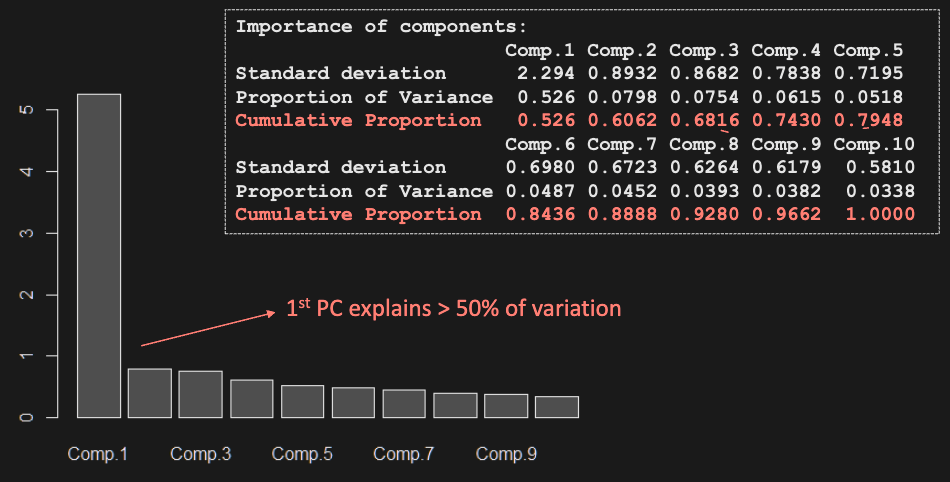
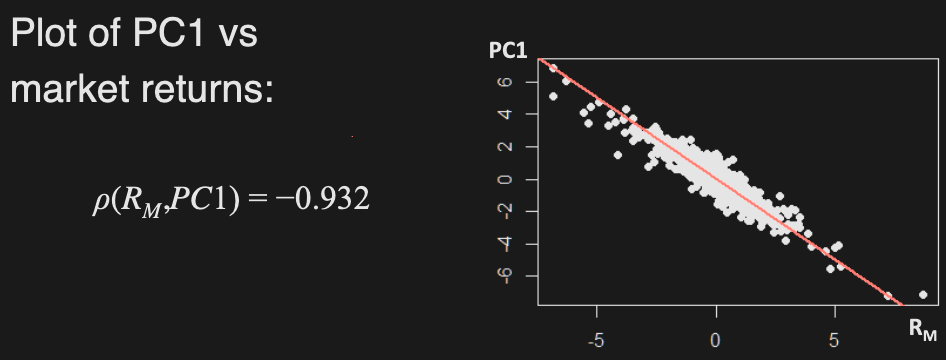
PCA can be used to identify components that explain overall variation of data, but it does not always give meaningful PC’s - PC’s are just transformations that capture the most variability, they do not explain how data was generated.
For a proper data-generating model, use Factor Analysis:
Factor Analysis
Assuming , the return variance becomes
We need to estimate and variances using maximum likelihood.
A rotation of (scaling it with orthogonal matrix P) has no effect on the model:
We need further constraints on . A common constraint is to rank factors by explained variability, similar to PCA.
W6: Risk Management
Types of risks
• Market risk: due to changes in market prices
• Credit risk: counterparty doesn’t honour obligations
• Liquidity risk: lack of asset tradability
• Operational risk: from organization’s internal activities (e.g. legal, fraud, or human error risk)
Risk measures
-
There exists different notions of risk (losing money, bankruptcy, not achieving desired return), but in practice risk measures are used to determine the amount of cash to be kept on reserve
-
Return volatility is not a good risk measure. The following distributions have the same , but their risk profiles are very different
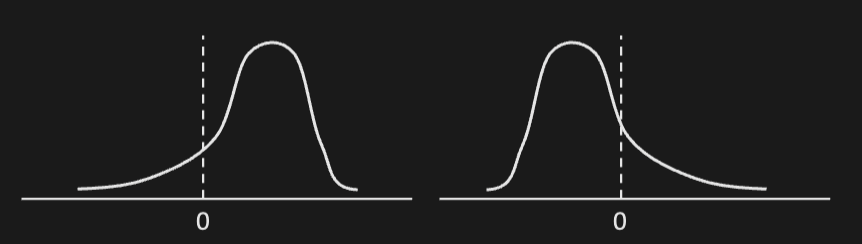
- LHS: average return is positive but it has a fat left tail, so returns could be large negative values
- RHS: average return is negative, but no chance of getting very large negative values; hence less risky
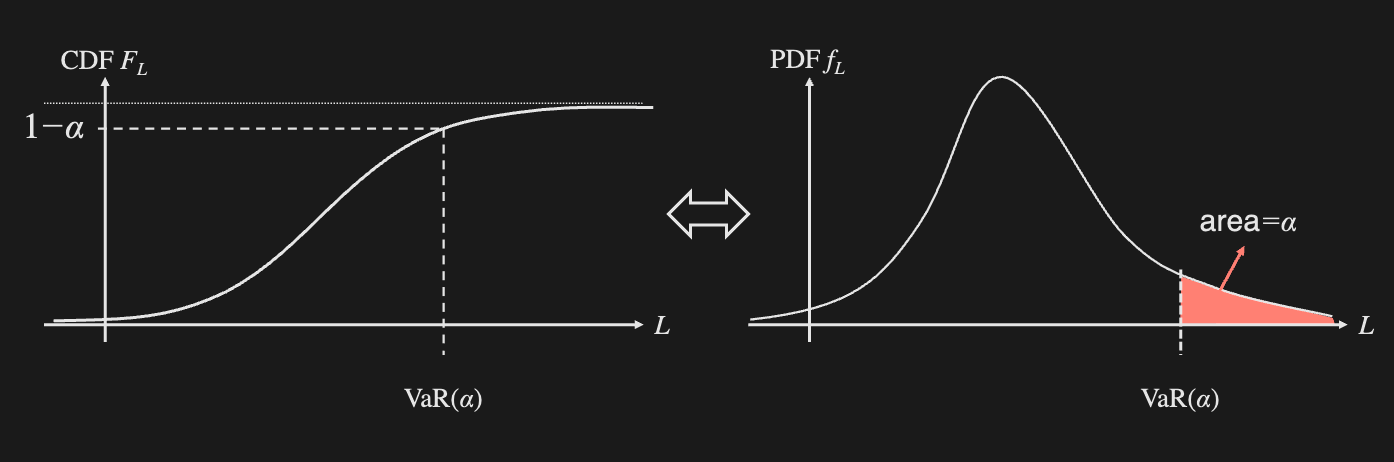
Value at Risk (VaR)
The VaR is the amount that covers losses with probability .
Let be the loss of an investment over time period . (, where is revenue).
The VaR is defined as the quantile of for some :
For a continuous RV with CDF , it is defined as:
E.g. Consider asset with annual log-returns. Find the 95% confidence level annual VaR for a $1000 investment in this asset.
Want to find VaR() s.t.
Formula for VaR given log returns:
Limitations
VaR can be misleading as it hides tail risk and discourages diversification.
However, it is still widely used due to the Basel framework (banking regulations).
As an example, the following have the same VaR but vastly different risk
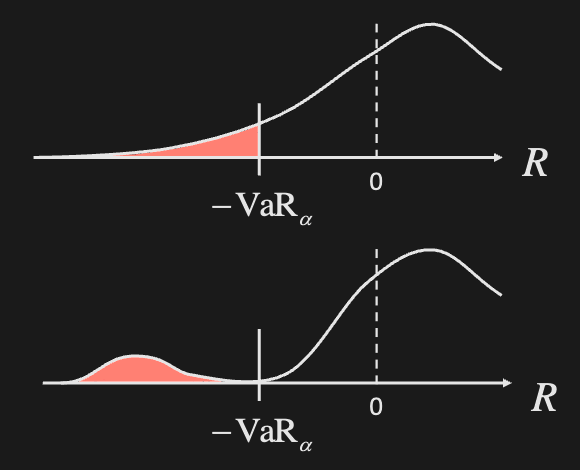
Solution: use conditional VaR / expected shortfall
Conditional VaR / Expected Shortfall
Defined as the expected value (or average) of losses beyond VaR
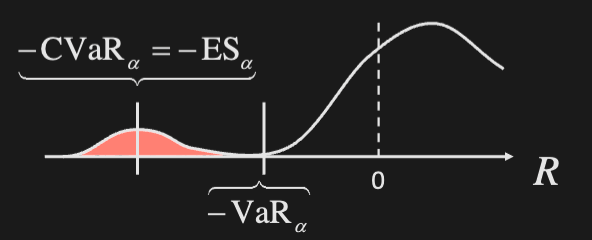
Examples
VaR & CVaR of a Normal Variable
If R~N(0, 1), find ES at confidence level
Let denote the top -quantile of the standard normal
Normal pdf:
Standard normal pdf:
More generally, for
Risk measure properties
Let denote a risk measure for an investment with loss L.
A coherent risk measure must satisfy the following properties:
- Normalized (the risk of holding no assets is 0)
- Translation invariance (adding loss to portfolio increases risk by )
- Positive homogeneity
- Monotonicity
- Sub additivity (due to diversification)
E.g. Show that VaR and CVaR are translation invariant and positively homogeneous
Let , then
E.g. Consider 2 risky zero-coupon bonds priced at 100 face value. If each one has 4% independent default probability, show that is not sub-additive.
Distribution of or :

Distribution of :
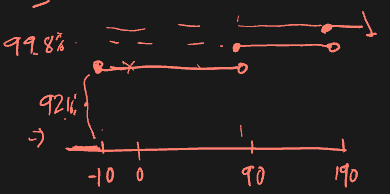
which is greater than
This shows that under VaR, owning both bonds is riskier than owning them separately. VaR is thus incoherent at the 5% level (it hides tail risk). At 3%, it would be coherent.
E.g. Show that is sub-additive.
We see that
Entropic VaR
EVaR is a coherent alternative to VaR based on the Chernoff bound, which is attained by applying Markov’s inequality to . It is an exponentially decreasing upper bound on the tail of a RV based on its MGF.
Markov inequality: for a positive RV , we have
For loss RV with MGF , we have
Bound this by and solve for :
Thus, EVaR is defined as
EVaR of a Normal Variable
The MGF of a Normal variable is
EVaR is the infimum of the following:
To find infimum (minimum) over z>0, differentiate and set to 0:
So we have
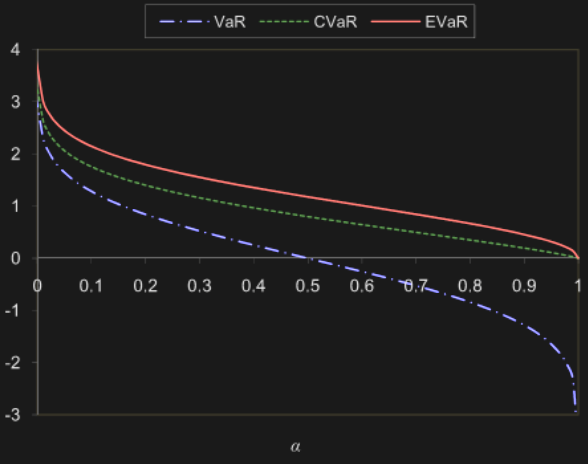
Calculating risk measures
3 ways:
- Parametric modeling
- Historical simulation
- Monte Carlo simulation
Other risk management techniques: stress-testing (worst-cast scenario) and extreme value theory (EVT)
~85% of large banks use historical simulation, the remaining use MC simulation
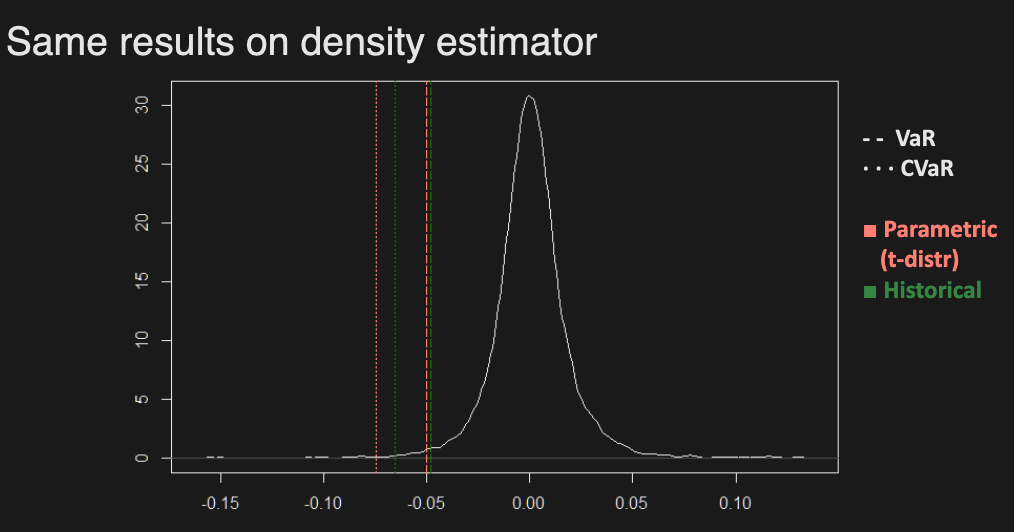
Parametric modeling
Fitting a distribution to revenues/returns and calculating VaR or CVaR/ES based on distribution
E.g. Assuming net returns of an investment follow a normal distribution, then for an initial capital , the parametric VaR and CVaR at confidence are
where are sample estimates, and are standard normal cdf, pdf.
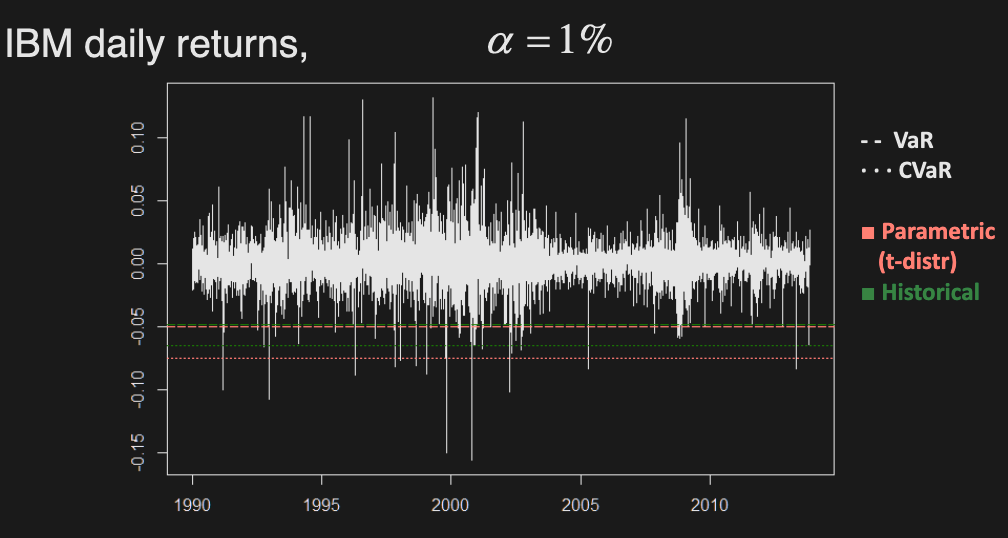
Historical simulation
Instead of assuming a specific distribution, it uses the empirical distribution of returns estimated by historical data.
Monte Carlo simulation
Even if returns are parametrically modelled, their resulting distribution is often intractable.
E.g. Consider a portfolio of 2 assets - one with normal returns, one with t-distributed returns. The distribution the portfolio return is not explicitly known.
We can simulate returns from such a model and treat simulated values as historical returns.
Time Series Models
Static models assume independence over time (but allow dependence across assets)
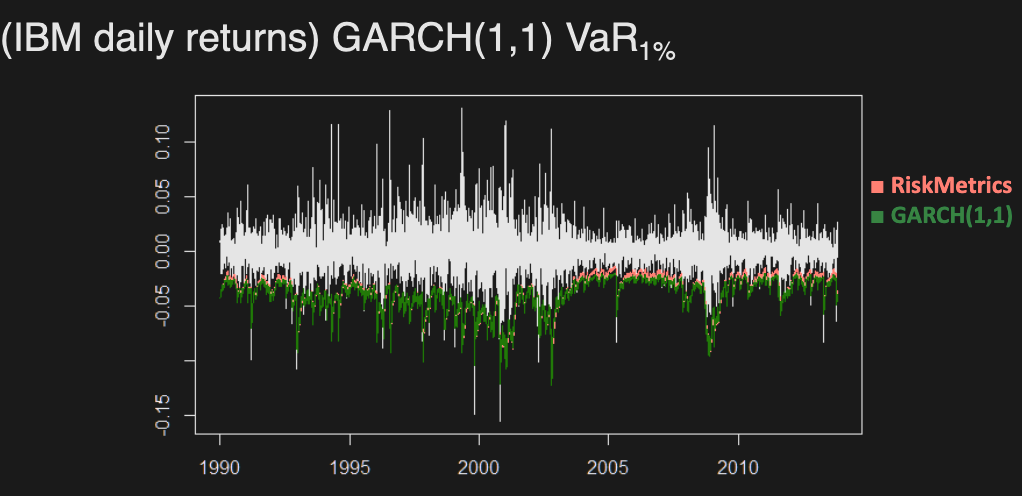
RiskMetrics Model
A simple time series model using the exponentially weighted moving average for return volatility
where
Typically, use for daily returns
GARCH(p, q) Model
where are iid and
W7: Betting Strategies
If we have a sequence of gambles where we have a positive expected payoff, how do we wager our bets for optimal results? We will look at a few different strategies below.
Setup. Consider a sequence of independent & identical gambles with
- Let p = P(win)
- For each $1 placed, the payoff is
Starting with initial wealth , assume you bet a constant amount at each step. Find expected wealth after n steps (ignoring ruin: for some )
Define indicator RV of winning i-th bet:
Notice that if , could be negative. Otherwise, we can expect to have some positive wealth at time n which increases linearly. The variance increases quadratically.
Assume we bet $1 at each step. Start with . Find the probability of eventual ruin, i.e. for some n.
Let and
Assume solution of the form
Solve quadratic:
If , then . This is a trivial solution (probability of ruin = 1 at all times).
So , and the probability of eventual ruin is
Assume we bet everything (entire wealth) at each step. What is our expected wealth after steps, not ignoring ruin?
Note that as since 2p>1. Wealth will grow exponentially.
Assume we bet a fixed fraction of wealth at each step. What is our expected wealth after steps?
This step uses the PGF (probabilistic generating function) of Binomial(n, p):
Continuing:
We have exponential growth and a low probability of ruin.
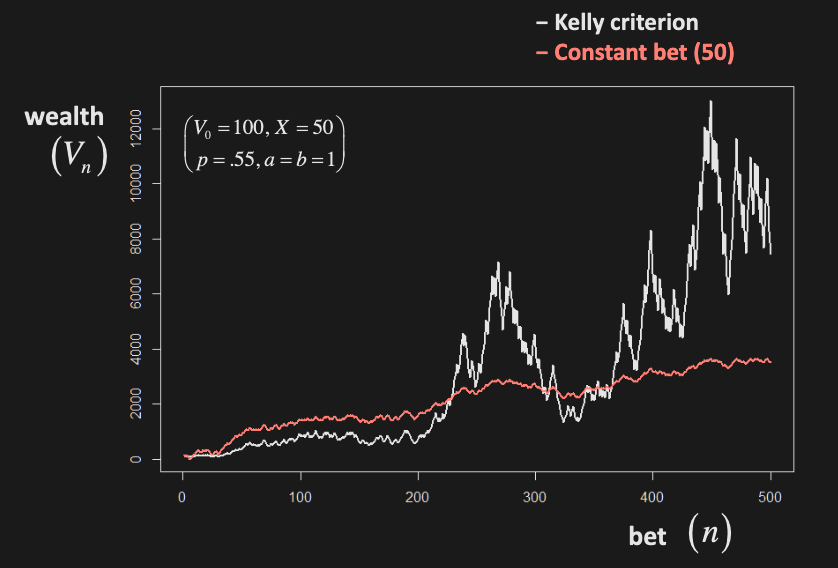
Kelly Criterion
Bet fraction of wealth that maximizes expected log return (or equivalently log of , or geometric average of returns).
Note: by Jensen’s inequality, maximizing log wealth != maximizing wealth, i.e.
What is the optimal value of the fraction?
Now maximize G(f) w.r.t. and set to 0
The optimal fraction is the difference between P(win) and P(lose).
What is the geometric average of the returns as ?
Denoting the growth rate from to with , the geometric average is
where
By SLLN, as , so the geometric average
General Setup
Now consider a general sequence of bets, where $1 bet +$a if win and −$b if lose. (In previous examples, a = b = 1, and the bet is favourable, i.e..)
The Kelly criterion optimal fraction to bet is: (Proved in PS 7.1b)
In the following example, f = 0.55 - 0.45 = 0.1
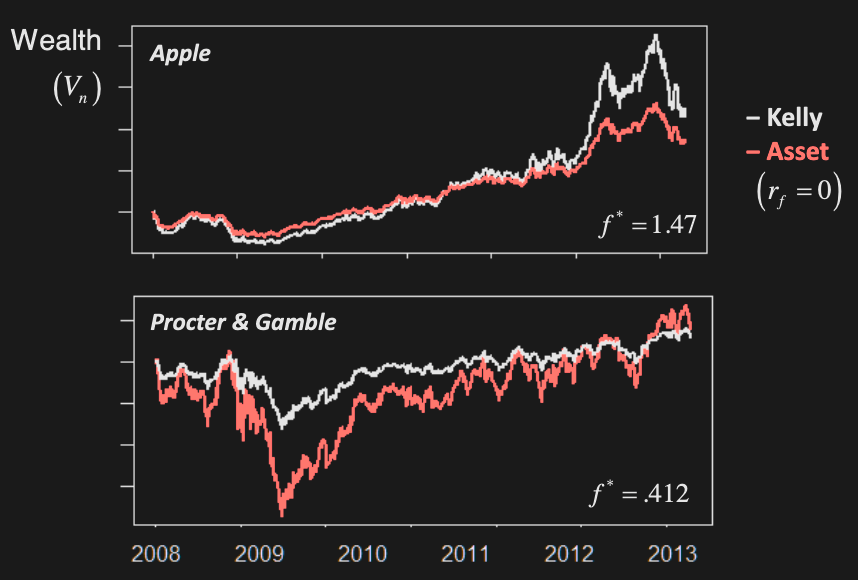
Investing Example
Now consider the following. We have a…
- risk free asset with return
- risky asset with return :
We invest fraction f of wealth into risky asset & remaining (1–f) into risk-free asset.
Apply Kelly Criterion to find f that maximizes logarithm of wealth:
Use Taylor expansion for around
Applying this, we get
Differentiate w.r.t. f and set to 0:
Since , we have
Theoretical properties
In the long term () with probability 1, a strategy based on Kelly criterion:
- Maximizes limiting exponential growth rate of wealth
- Maximizes median of final wealth
• Half of distribution is above median & half below it - Minimizes the expected time required to reach a specified goal for the wealth
Criticism
- Can have considerable wealth volatility (b/c of multiplicative bet amounts)
- Does not account for the uncertainty in probability of winning
- Many practitioners use fractional or partial Kelly, i.e. using smaller than Kelly fraction (e.g., f*/2)
- In practice, investing horizons are not infinite and there are many other considerations (e.g. transaction costs, short-selling limits etc)
W8: Statistical Arbitrage
Statistical Arbitrage (StatArb) refers to trading strategies that utilize the “statistical mispricing” of related assets
StatArb strategies are typically short term and market neutral, involving long & short positions simultaneously
Examples of StatArb strategies:
• Pairs trading
• Index Arbitrage
• Volatility Arbitrage
• Algorithmic & High Frequency Trading
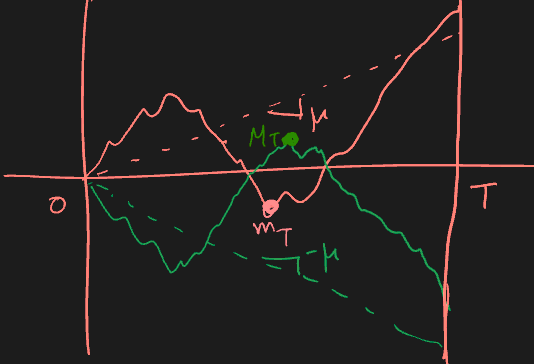
Pairs Trading
- Original & most well-known StatArb technique developed by Morgan Stanley quants
- Profit not affected by overall market movement (market neutral)
- Contrarian strategy profits from price convergence of related assets
Main idea
- Select pair of assets “moving together”, based on certain criteria
- If prices diverge beyond certain threshold, buy low sell high
- If prices converge again, reverse position and profit
Example
Let = price of lower asset, = price of higher asset.
- Open the position when prices diverge: buy $1 of low asset ( units), sell $1 of high asset ( units)
- cost =
- Close the position when prices converge
- profit = (c stands for closing)
Profitability is determined by asset price ratios (hence the use of log ratios for modelling):
The strategy is market neutral, i.e. profitability is not affected by market movement - Assets typically have common market betas
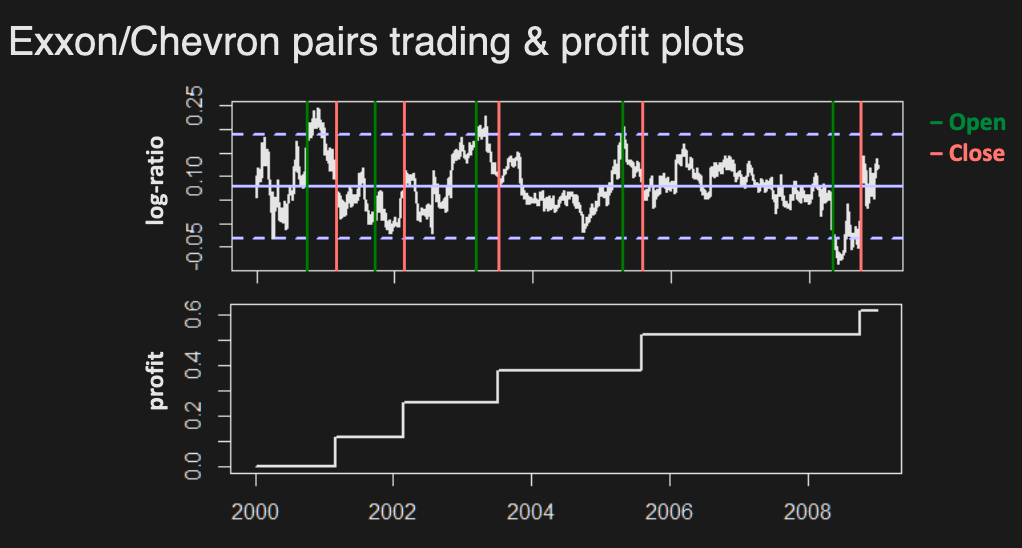
What can go wrong?
Prices may not converge.
Factors to consider
- Which pairs to trade
- When to open trade
- What amounts to buy/sell
- When to close trade
- When to bail out of trade
Most of these decisions involve trade-offs, so how do we select pairs to trade?
- Profitable pairs must have log-ratio with strong mean reversion
- Note: Mean reversion is not the same as simply having constant mean
Mean Reversion
Suggests log-ratio process is stationary
-
-
-
-
Autocorrelation function describes linear dependence at lag
Stationarity ensures process will revert back to its mean within reasonable time.
E.g. Let
If , what is the expected time until ? I.e. until
On any day t,
Let T = # days until for the first time. T is called hitting time, it is equal to # trials until 1st success (if ), so which has prob mass function
The expected time is hence
E.g. Let Brownian Motion (BM) (continuous time Random Walk)
For any , show that the expected time until is infinite.
Let = {first time standard BM with } hits level c Let
This means:
PDF of is given by
Integrated Series
A non-stationary time series whose difference is stationary
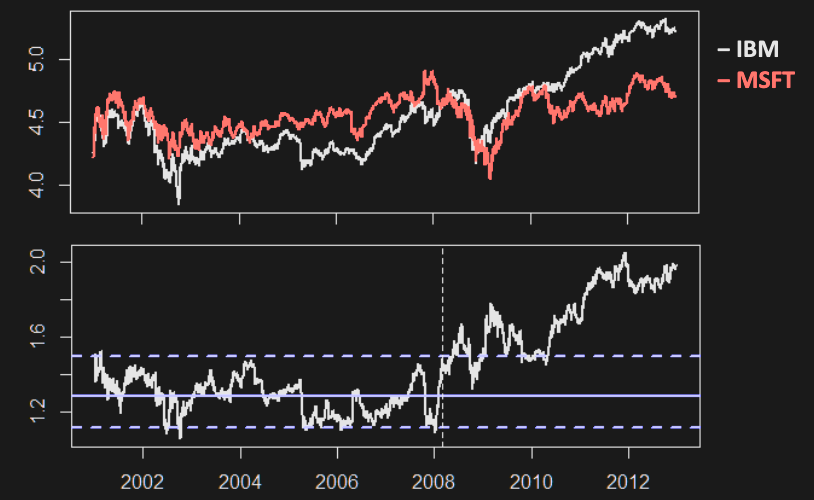
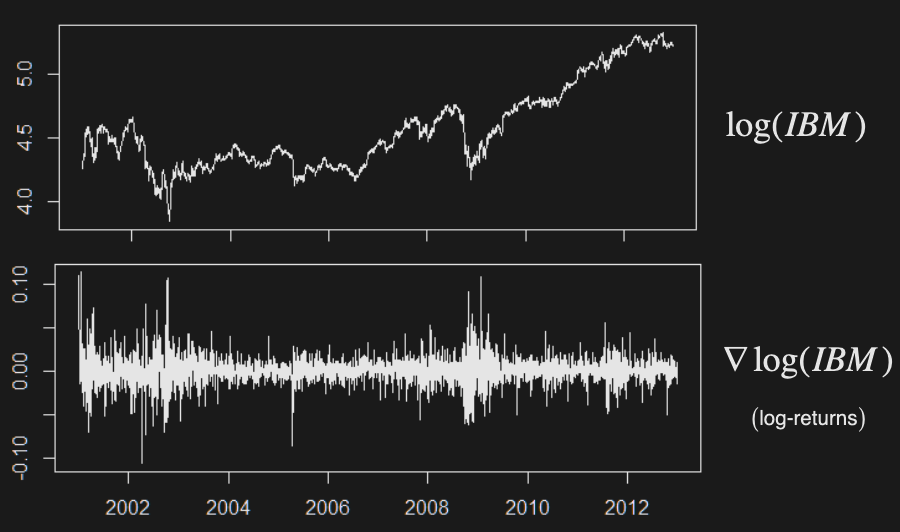
Asset log prices are not stationary - will need to apply differencing
Although follows a stationary process, is a random walk
Example: IBM stock price before and after differencing
Cointegration
Two integrated series are cointegrated if there exists a linear combination of them that is stationary.
Consider a vector of time series . If each element becomes stationary after differencing, but a linear combination is already stationary, then is said to be co-integrated with , which is the co-integrating vector.
There may be several such co-integrating vectors so that becomes a matrix. Interpreting as a long run equilibrium, co-integration implies that deviations from equilibrium are stationary, with finite variance, even though the series themselves are non-stationary and have infinite variance.
For pairs trading, we want to find assets which are cointegrated (their log difference is mean reverting, and thus stationary)
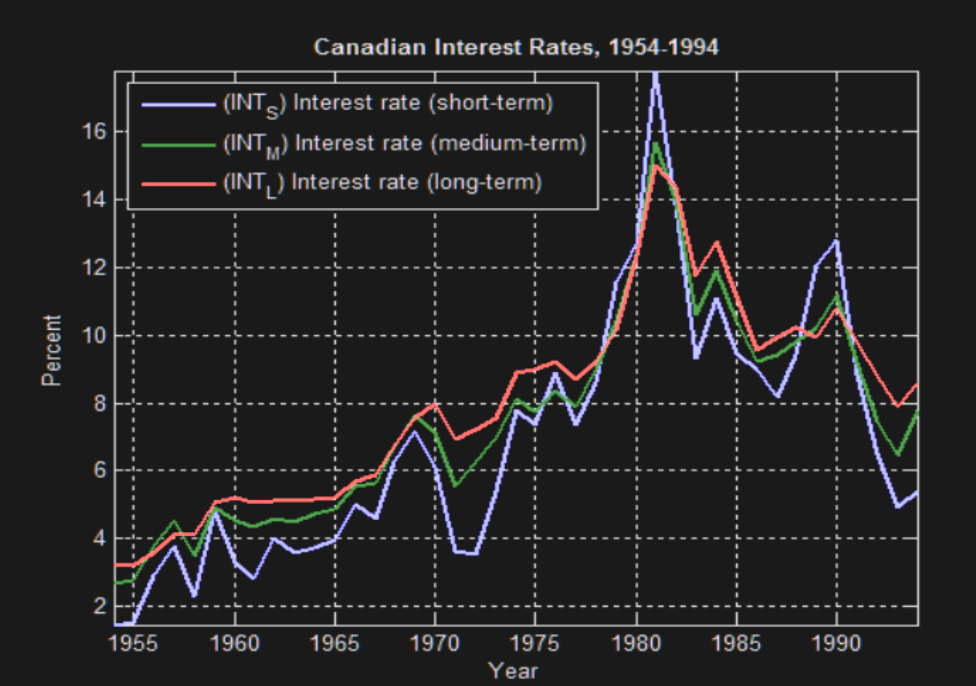
E.g. ST, MT, and LT interest rates are co-integrated - they move together but behave as random walks individually
E.g. Let be random walk, and where
Show that are cointegrated
First, we need to show are integrated (not stationary, with stationary 1st order differences).
Which is the same case for
Next, show cointegration by showing is stationary.
If |t-s| > 1,
If |t-s| = 1,
is thus stationary is integrated of order 1 (and similarly for )
is stationary, so are cointegrated.
Stationarity Tests
Hypothesis test for
Idea: fit to data and test
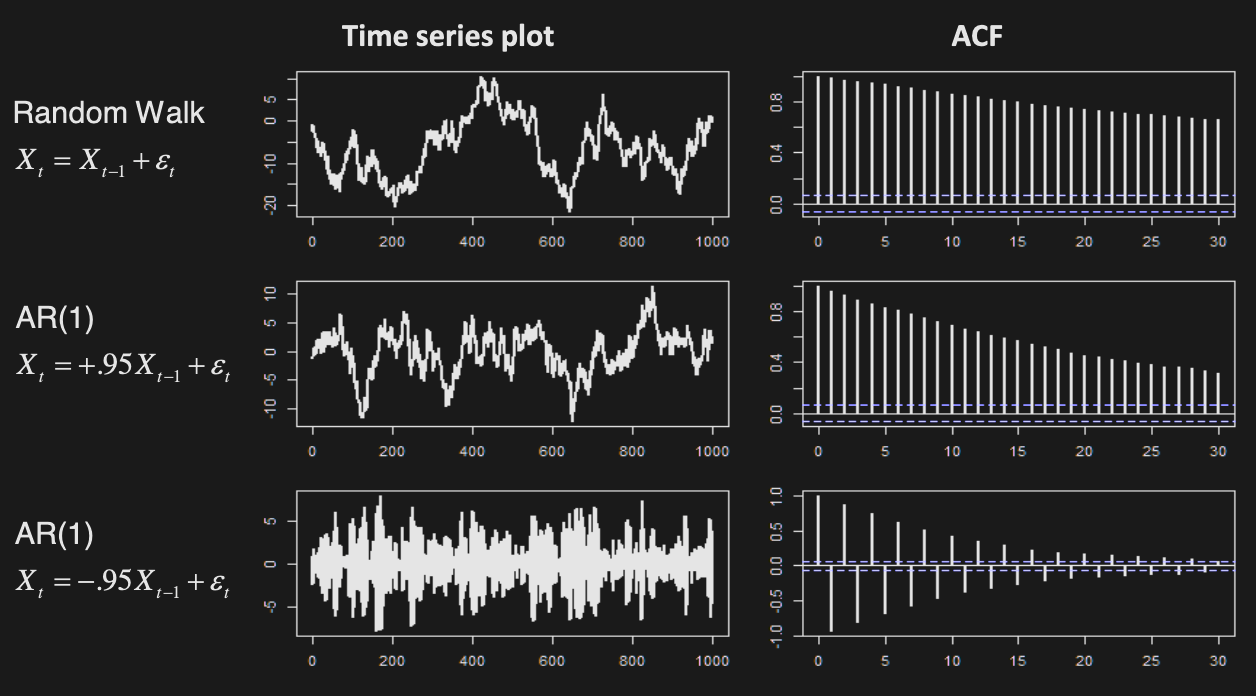
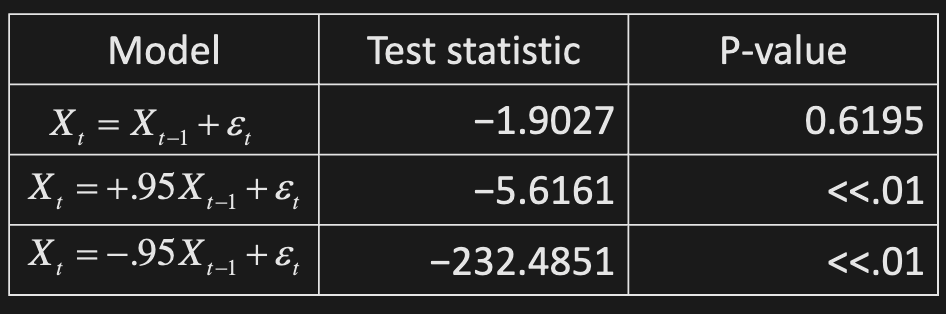
For random walk, we fail to reject the null hypothesis that is integrated.
Issue: we don’t know which linear combination to check for stationarity
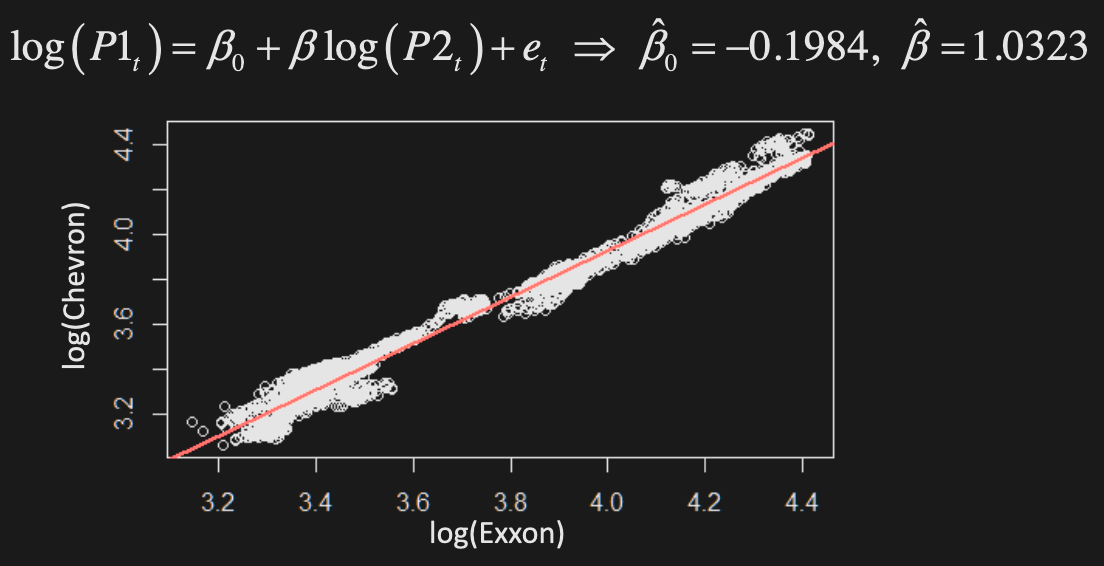
Two-step method
-
Estimate linear relationship between variables
-
Test resulting difference series (residuals) for stationarity
-
Example: regress Chevron on Exxon log-prices
- Then, test residuals for stationarity: reject the null hypothesis that it is integrated
-
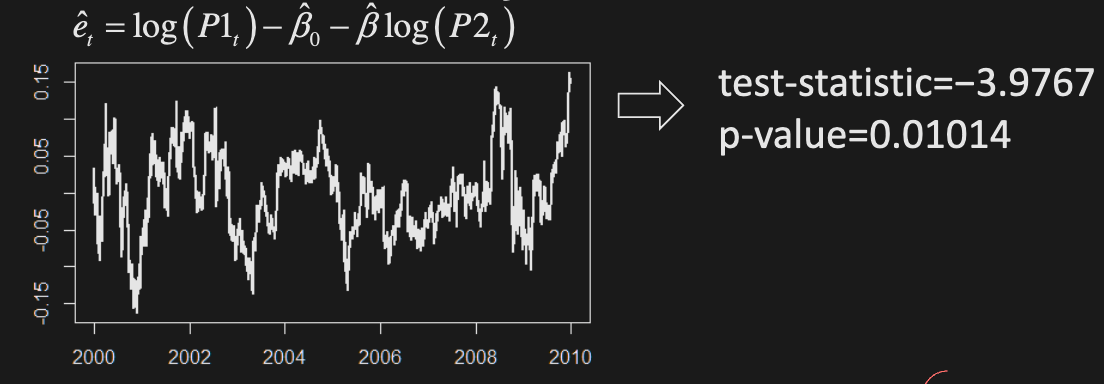
-
Problems:
- Regressing P1 and P2 can give different results than regressing the other way around.
- There is estimation error for residuals.
-
Can be used to address spurious regression
- Results of random walk (integrated series) regressions are NOT reliable
- Consider 2 independent random walks
- When you regress you are NOT guaranteed that as the sample size (i.e. not consistent)
- Results of random walk (integrated series) regressions are NOT reliable
Vector Error Correction models (VECM)
Combined treatment of dynamics & cointegration, using Vector AutoRegressive (VAR) models
Index Arbitrage
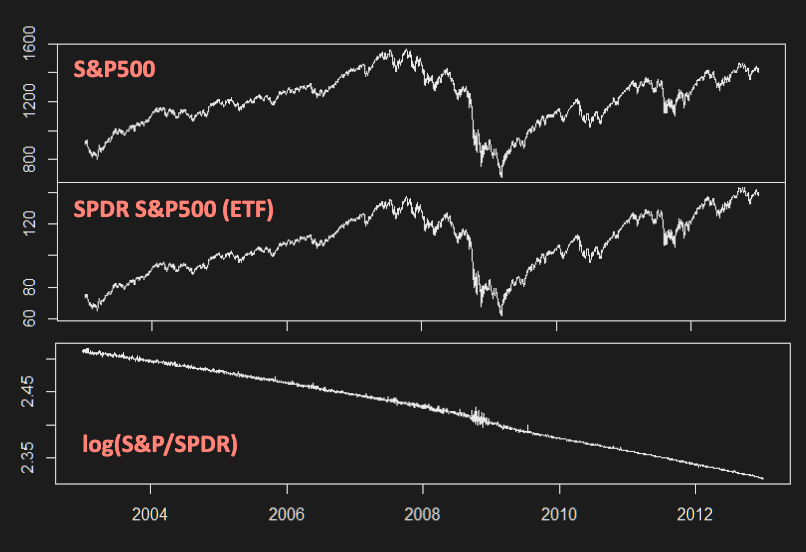
- Indices measure value/performance of financial markets
- Dow-Jones Industrial Average (DJIA): Simple average of 30 major US stock prices (since 1896)
- Standard & Poor (S&P) 500: Weighted (cap-base) average of 500 large NYSE & NASDAQ listed companies
- Financial indices are NOT traded instruments. However, there are many financial products whose value is directly related to indices:
- Mutual funds: e.g., Vanguard® 500 Index Fund
- Exchange-Traded-Funds (ETF’s): e.g., SPDR or iShares S&P500 Index
- Futures: e.g., E-Mini S&P futures
- Financial products based on indices essentially offer a sophisticated version of multivariate cointegration
- For an index of N assets w/ weights , the index level is
- It has a co-integrating relationship with , an instrument tracking index (e.g. futures)
Volatility Arbitrage
- VolArb is implemented with derivatives, primarily options
- The higher the volatility, the higher the option price
Consider European options:
-
For Black-Scholes formula, the only unobserved input is volatility , which has to be estimated
-
Implied volatility i s the input that makes Black-Scholes price equal to observed market price
- not estimated from underlying asset dynamics
-
If volatility will increase in the future, beyond what current options prices warrant (implied vol), some possible strategies are:
- straddles (long at the money call and put)
- strangles (long out of the money call and put)
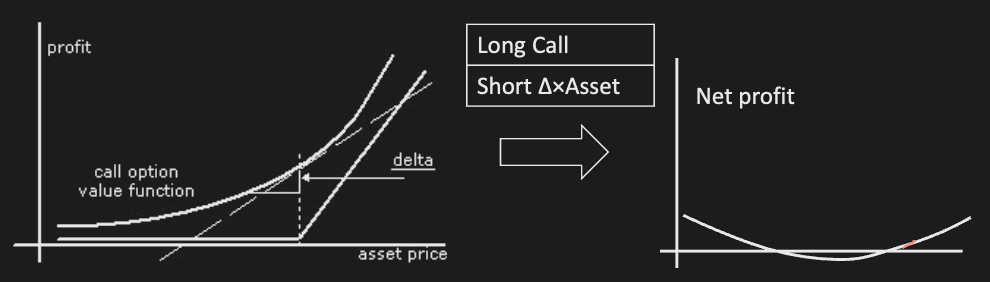
- delta-hedged long call or put
-
Delta-neutral strategies eliminate effects of asset movement
-
Common approach is to describe the evolution of volatility with GARCH (Generalized AutoRegressive Conditional Heteroskedasticity) models
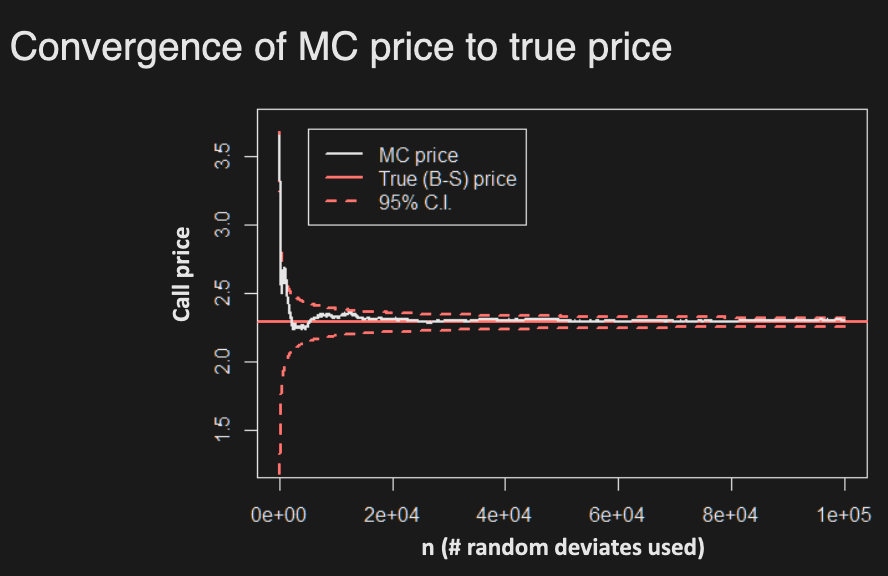
W9: Monte Carlo Simulation
Numerical Option Pricing
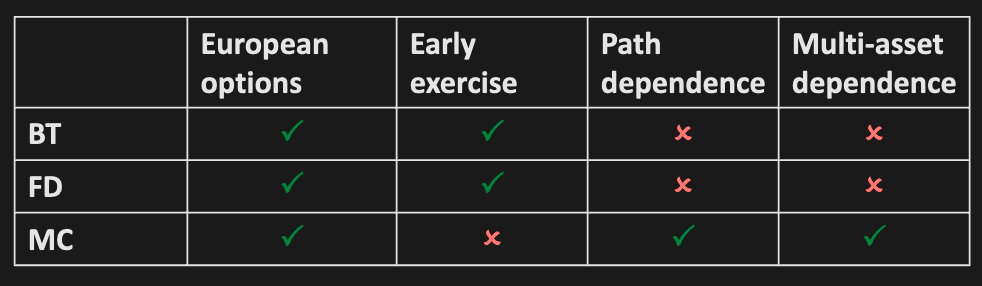
3 basic numerical option pricing methods:
- Binomial trees
- Finite difference (based on Black Scholes PDE)
- Monte Carlo simulation (based on SDE for asset prices & risk neutral valuation)
Multivariate Normal Properties
If , then:
Marginals
Linear combinations
Conditionals
Notice how
Brownian Motion
forms the building block of continuous stochastic models
Recall Ito Processes from STAC70:
A (one-dimensional) Itô process is a stochastic process of the form
where and are adapted processes such that the integrals are defined. Equivalently, we can write this as
The Brownian motion is an Itô process. (Pick and .)
The general Brownian motion with (constant) drift (and constant volatility ) is an Itô process. (Pick and .)
Standard Brownian Motion
with the following properties:
Arithmetic Brownian Motion
with drift and volatility and the following properties:
SDE form:
E.g. For , find distribution of
For
For (Brownian Bridge)
Geometric Brownian Motion
Process whose logarithm follows ABM
SDE form:
Risk Neutral Pricing
A risk-neutral (RN) measure or equivalent martingale measure (EMM) is a probability measure under which discounted asset prices are martingales.
Martingale: a stochastic process with the property
Assuming GBM for asset and risk-free interest rate , there exists a probability measure such that
The arbitrage-free price of any European derivative with payoff is given by discounted expectation w.r.t. RN measure
E.g. Show that under RN measure, . More generally, .
Use the Normal MGF:
If , then
E.g. Find price of forward contract (no dividends)
We know (forward contracts involve no cashflow at t=0)
By risk neutral pricing,
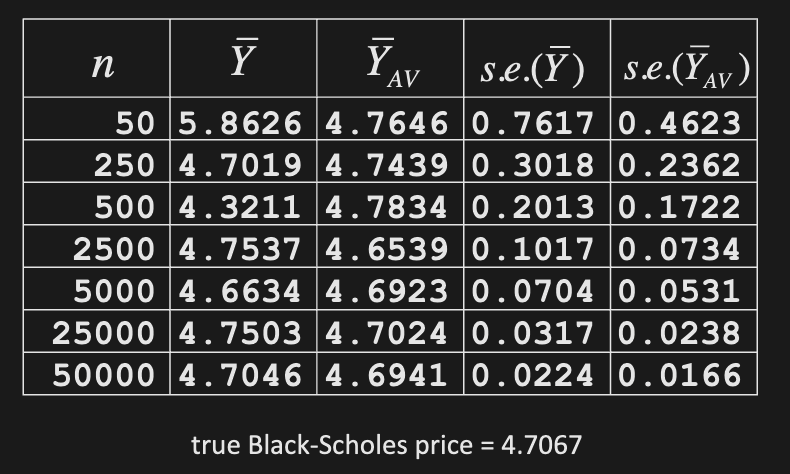
Estimating Expectations
If cannot be calculated exactly, it can be estimated/approximated by simulation:
- Generate N independent random variates based on RN measure (i = iterations, not time)
- By Law of Large Numbers (SLLN)
- Moreover, by Central Limit Theorem (CLT)
E.g. Show estimator of is consistent, and build 95% confidence interval for
Estimator:
Build a 95% confidence interval for as well
Confidence interval:
European Call
Estimate European call price w/ simulation
- Asset price dynamics:
- Payoff function for strike K & maturity T:
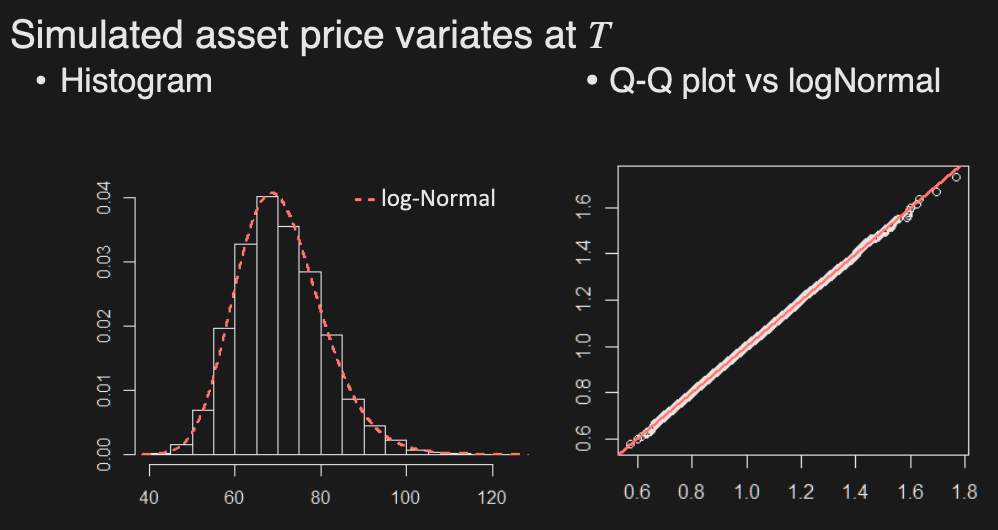
Generate random asset price variates as:
where is standard Normal variate
Multiple assets
Payoff of some options depends on prices of multiple assets
E.g. exchange (outperformance) option w/ payoff
Monte Carlo option pricing requires simulating and averaging multiple asset prices/paths. We cannot simply simulate each asset separately since there could be cross-asset dependence.
Multivariate Brownian Motion
Define -dimensional standard BM
to have independent Normal increments
Note: increments are independent over time, but can be dependent across dimensions!
Multivariate ABM
w/ SDE , where
-dim. standard BM W/ correlations
, where
Cholesky Factorization
A simple way to generate correlated Normal variates from independent ones
For a positive definite matrix where , the Cholesky decomposition gives
It’s essentially the square root matrix.
If and is the Cholesky factorization of the covariance matrix , then
Note that is lower diagonal.
E.g.
where
The covariance matrix can be decomposed as
Note that
W10: Pricing Exotic Derivatives
Path Dependent Options
Derivatives whose payoffs depend on (aspects of) the entire asset price path, instead of just the final price
Barrier Options
Options that come into existence/get knocked out depending on whether prices hit a barrier. Final payoff is equal to a call/put.
4 types of Barrier options:
Up-and-out (U&O):
- gets knocked out if prices moves above the barrier
- max must be below barrier for the option to be worth something
Down-and-out (D&O):
- gets knocked out if price moves below the barrier
- min must be above barrier for the option to be worth something
Up-and-in (U&I):
- comes into existence if price moves above the barrier
- max must be above barrier for the option to be worth something
Down-and-in (D&I):
- comes into existence if price moves below the barrier
- min must be below barrier for the option to be worth something
E.g. When (barrier < strike), b/c the payoff is not >0
Note that combining “out” and “in” options with the same B, K, T, etc. gives us a vanilla option. E.g.
Pricing
Notation:
The prices are:
Simulating GBM paths
To price general path dependent options, we need to simulate asset price paths
In practice, we discretize time and simulate asset price at m points:
For GBM, has solution:
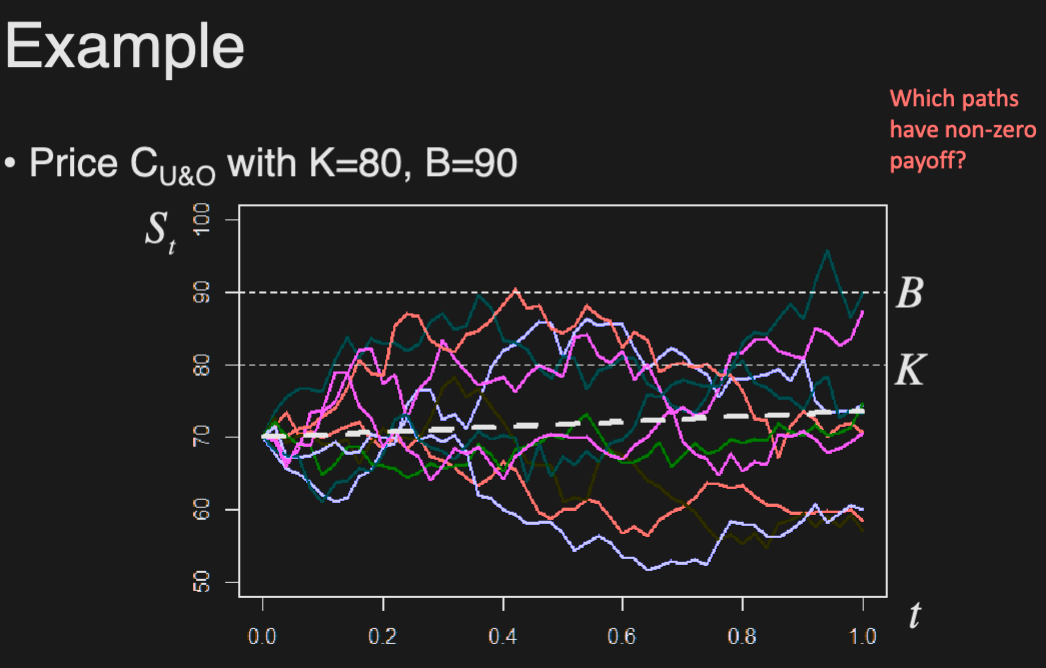
Only the neon purple option has a non-zero payoff, since it hasn’t been knocked out (exceed B), and is above K
Monte Carlo for Barrier Options
MC for barrier options based on simple discretization leads to biased prices!
All knock-out option prices will be overestimated, because the discretized minima/maxima will not be as extreme as the true ones (there may be some time point we did not simulate, during which the barrier could have been crossed, making the option worthless). Similarly, the knock-in option prices will be underestimated.
Bias can be reduced by increasing number of steps (m) in time discretization, but the computation would become increasingly expensive.
Trade-off between # paths (n) & # steps (m):
- n↑ Var↓ & m↑ Bias↓ (Bias-Variance trade-off)
Reflection principle
If the path of a Wiener process reaches a value at time , then the subsequent path after time has the same distribution as the reflection of the subsequent path about the value .
Max of standard BM ~ absolute normal
For standard BM , the max by time T, is distributed as a folded normal.
We want to find the CDF
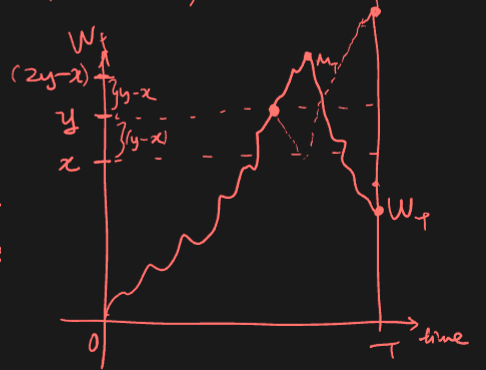
For
When , we have
Thus (consider first line vs last line above).
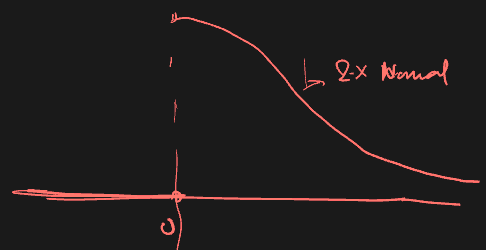
E.g. Find the probability that standard BM hits barrier before time
Since , we have
Optimal n/m ratio
MC estimates of using path discretization w/ different n (paths), m (steps)
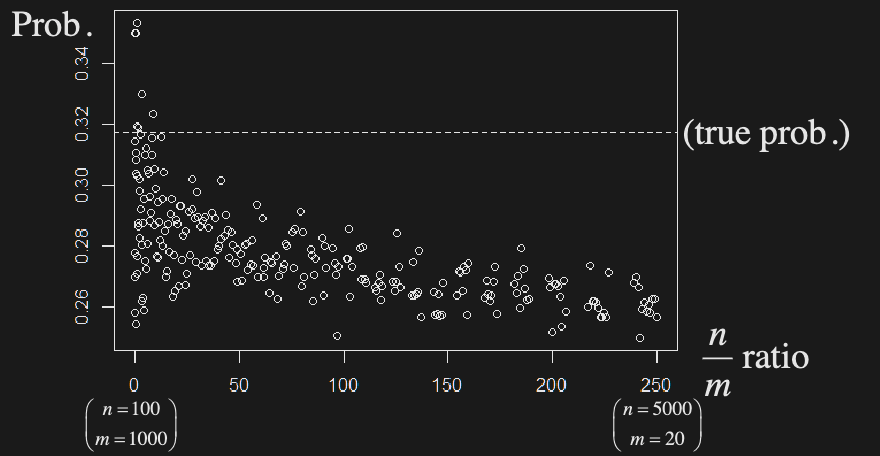
Best MSE lies in the middle:
- High variance when n/m is low
- High bias when n/m is high
E.g. Estimate probability that standard BM hits 1 before time 1, with MC but without bias.
Generate values of directly by generating and setting . Then, estimate the probability by the proportion of that are
Below are MC estimates of using direct simulation of w/
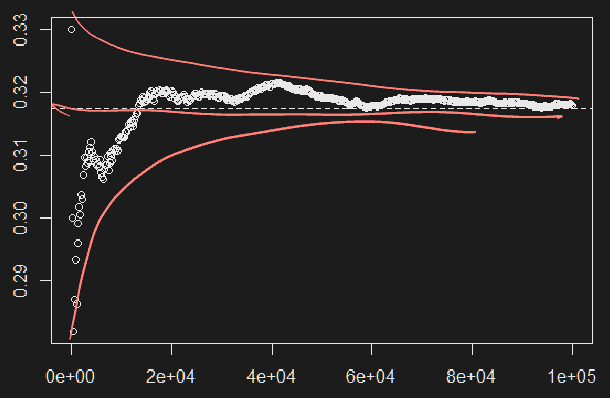
Extrema of Brownian Motion
- For standard BM , maximum is distributed as
- For arithmetic BM , the distribution of the maximum is difficult to work with - reflection principle does not work b/c of drift
- However, one can easily simulate random deviates of maximum using Brownian bridge (Brownian motion with fixed end point)
- Its construction allows for general treatment of extrema of various processes
Consider ABM:
Conditional on , the maximum of the Brownian bridge process has a Rayleigh distribution:
Note that distribution of conditional maximum is independent of the drift, given
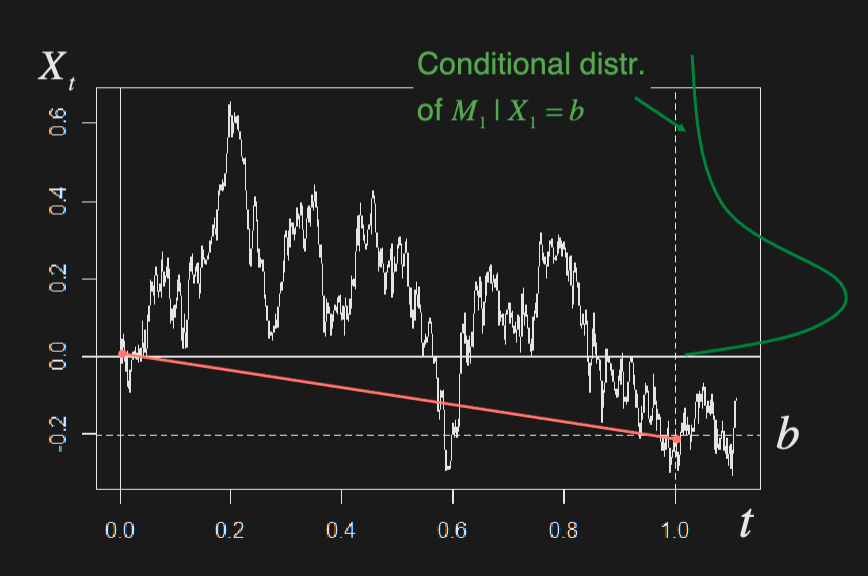
Simulating maxima of ABM
- Generate
- Generate
- Calculate
For maxima of GBM, exponentiate ABM result
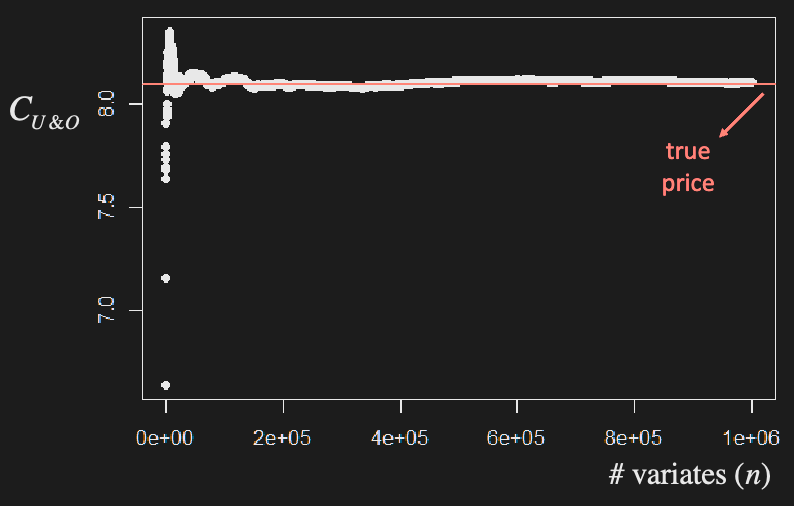
Simulating minima of ABM
By symmetry, min of ABM with max of ABM with
Time Discretization
Path dependent options generally require simulation of entire discretized path. Exceptions are options depending on maximum (e.g. barrier, look-back).
If prices do not follow GBM, it is generally not possible to simulate from exact distribution of asset prices, so we need to approximate sample path distribution over discrete times
Euler Discretization
Consider a general SDE where drift/volatility can depend on time and/or process
There is no general explicit solution for , i.e. distribution of is unknown (in closed form)
To approximate the behaviour of :
- Discretize time
- Simulate (approx.) path recursively, using
To approximate distribution of , generate multiple (#n) discretized paths
W11: Simulation - Variance Reduction Techniques
Antithetic Variables
For each normal variate , consider its negative . Note that they are dependent. For Uniform(0, 1), use and
Calculate the discounted payoff under both:
Estimate price as the mean of the RVs
The idea is to balance payoffs of paths with opposite returns.
Pros and cons
This technique is simple, but not always useful. It only helps if the original and antithetic variates are negatively related.
We can prove this by comparing its variance to the variance of the naive mean . Under what condition does the variance get reduced?
Variance reduction proof
Variance of naive mean:
Variance of antithetic mean:
For to hold, we must have
Even function => worst case scenario (-Z gives the same value)
Asymptotic distribution of estimator
Find asymptotic distribution of antithetic variable estimator in terms of moments of
By CLT, we have
where the mean is
and the variance is
Example
Antithetic variable pricing of a European call
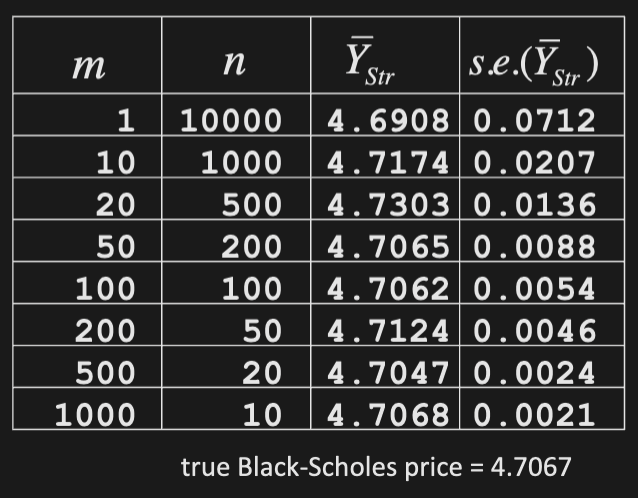
Stratification
Split the RV domain into equiprobable strata, and draw equal number of variates from within each one
Consider equiprobable Normal strata
Stratified estimator of is given by
where is the estimator within each stratum , and
Mean of estimator
Verify that is an unbiased estimator of
Variance reduction proof
Show that
So we have since by Jensen’s inequality
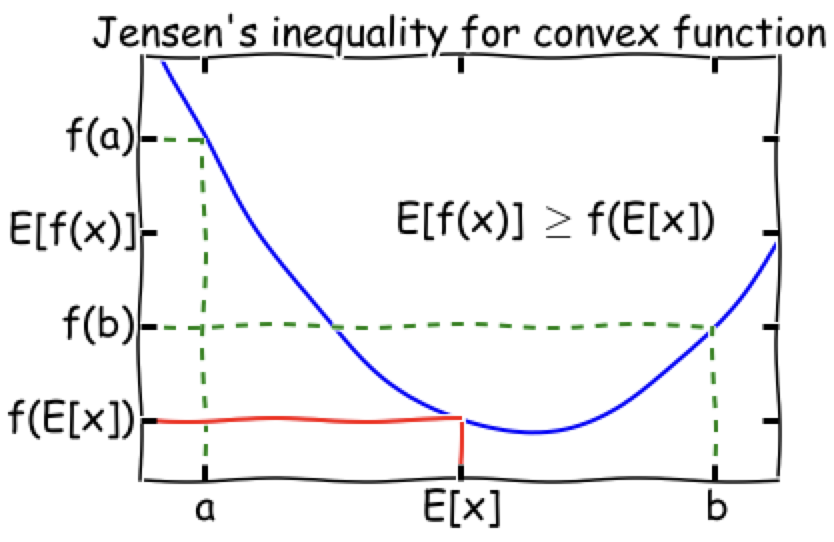
So for , a convex function, we have
Pros and cons
This method ensures equal representation of each stratum in the RV’s domain. It always reduces variance.
It works best when target RV (payoff) changes over its domain, i.e. is highly variable (as opposed to a flat payoff).
It is computationally difficult for multidimensional RV’s. Getting the conditional distribution within each stratum can be difficult, and the CDF is often unknown.
Example
Stratified pricing of a European call
Control Variates
Estimate using MC: generate iid and use
where is option’s discounted payoff
Assume there is another option with payoff whose price is known. The idea is to use MC with the same variates to estimate both and , but adjust the estimate to take into account the error of estimate . E.g. if underestimates , then increase .
Adjust for estimation error linearly, as
where the coefficient controls adjustment.
Mean of estimator (unbiased proof)
Show that is unbiased for any (provided are unbiased)
Variance of estimator
Optimal value of adjustment coefficient
Show that the optimal value of is . This is the regression slope coefficient.
In practice, are unknown, so we estimate using MC sample
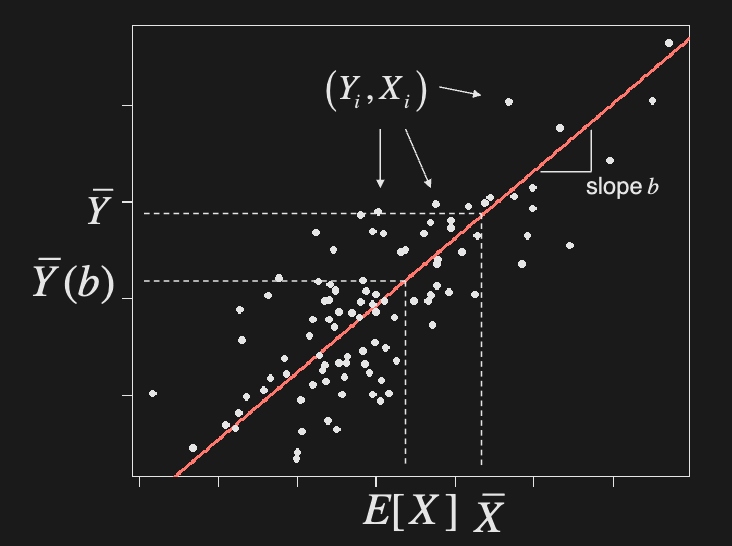
Optimal variance
Show that the optimal variance is
In practice, we need to use sample estimates of
Correlation of control
Good control variates have high absolute correlation with option payoff (high )
- In-the-money call:
- Out-of-the-money call:
- In-the-money put:
- Out-of-the-money put:
Example
Price European option using final asset price () as control, assuming GBM with
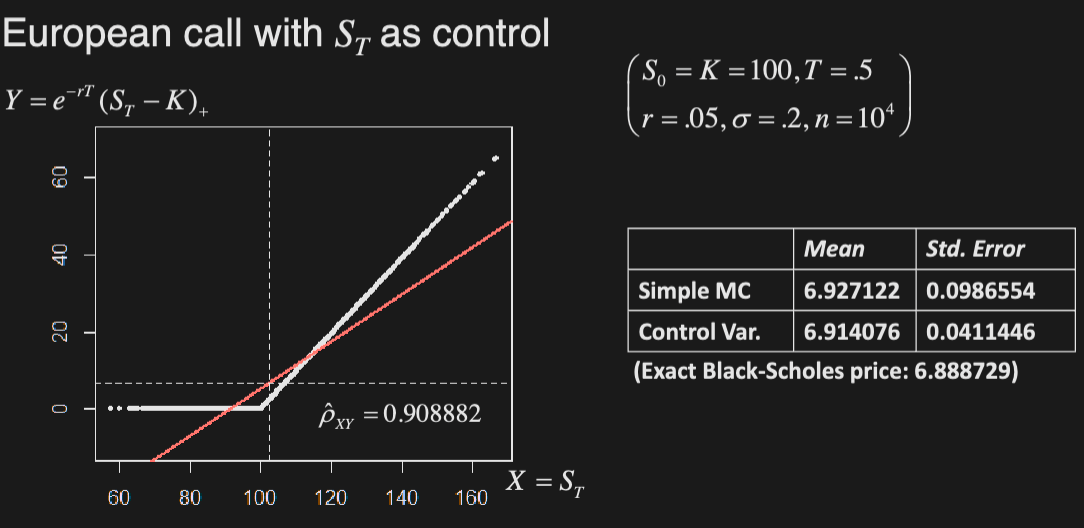
Importance Sampling
We can reduce variance by changing the distribution (probability measure) from which paths are generated to give more weight to important outcomes, thereby increasing sample efficiency. The performance of this method relies heavily on the equivalent measure being used.
E.g. for European call, we put more weight to paths with positive payoff (i.e. paths for which we exercise)
Let be pdf of , we want to estimate
Using simple MC, generate sample . The estimate is thus If we have sample from a new pdf , we can still estimate as follows
Mean of estimator
Note that this estimate is unbiased (provided simple MC estimate is unbiased).
Variance of estimator
Variance reduction proof & condition
Show that
The LHS is equivalent to
Optimal variance condition
Show that for positive , if
i.e. importance sampling works best when new pdf resembles (payoff original pdf)
Multiple random variates
Importance sampling can be extended to multiple random variates per path
For example, for a path-dependent option with payoff , which is a function of m variates forming discretized path, the mean of the estimate is
If in addition, , , then
Example
Consider a deep out-of-the-money European call with
With simple MC, generate final prices as
Which of the following is a better candidate for ?
The former, since it is ITM. We want to simulate from distributions with higher means (closer to ).
W12: Optimization in Finance
Most real world problems involve making decisions, often under uncertainty. Making good/optimal decisions typically involves some optimization.
In finance, we must typically decide how to invest over time and across assets.
E.g. mean-variance analysis or Kelly criterion
Types of Optimization Problems
- Straightforward (closed form or polynomial complexity):
- Linear, quadratic, convex
- Equality/linear/convex constraints
- Difficult:
- Discrete optimization (discrete variable)
- E.g. indivisible assets, transaction costs
- Dynamic optimization (previous decisions affect future ones)
- Investing overtime
- Stochastic optimization (uncertainty)
- Discrete optimization (discrete variable)
Discrete & Dynamic Optimization
Assume you can perfectly foresee the price of a stock. You want to make optimal use of such knowledge, assuming
- you can only trade integer units of the asset
- every transaction costs you a fixed amount
- you cannot short sell the asset
This is a discrete, dynamic optimization problem. Although there is no randomness (we have perfect knowledge), the problem is not trivial.
We could consider all possible strategies, but that would be expensive - the search space size is .
We can use dynamic programming (backward induction) instead:
- At any time t, there are 2 states: owning or not owning the asset
- The optimal value of each state at t = the best option out of transitioning to another state + the optimal value of that state at t+1
- Start from the end, and consider optimal value going backwards to discover the best strategy
E.g. Find evolution of value, assuming no position at and
Let asset price at , transaction cost, opt. value for no position at , opt. value for long position at
| state \ time | t=1 | t=2 | t=3=n | > n |
|---|---|---|---|---|
| no position | 0 | |||
| long position | / | / |
E.g.
Stochastic Optimization
Consider a similar problem without exact price knowledge (e.g. prices follow binomial tree with some probabilities)
We want to find the best trading strategy (which maxes the expected P&L)
Define the following:
- is the state RV (price and position, e.g. long/short)
- is action (change in state e.g. buy/sell)
- is a reward function (e.g. cashflow)
We want to maximize expected reward over stochastic actions
Letting be the optimal value function, we have
E.g. Consider the following Binomial tree, with up/down probability of 1/2:
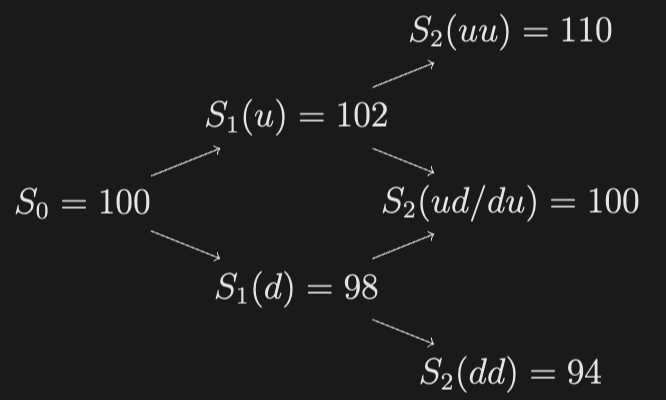
Find the optimal strategy that maximizes the expected assuming you can long and short the asset, and there is a transaction cost of $0.1/share. Note that there are three possible states now (long, neutral, short), and possible strategies. Find the optimal strategy and its value using dynamic programming, and optionally verify it with an exhaustive search.
Solution: It is not difficult to reason that the best strategy is to go long at and short at , since the up paths have positive expected and the down paths have negative expected (greater than the transaction costs), and this strategy minimizes the expected costs (you only long/short when you need). You can actually verify this by calculating the expected of all 27 strategies by brute force (e.g., in R) to get:
| Strategy | Expected P//L |
|---|---|
| s,s,s | -1-2tc |
| s,s,n | -1.5-2tc |
| s,s,l | -2-3tc |
| s,n,s | 0.5-2tc |
| s,n,n | 0-2tc |
| s,n,l | -0.5-3tc |
| s,l,s | 2-3tc |
| s,l,n | 1.5-3tc |
| s,l,l | 1-4tc |
| n,s,s | -1-2tc |
| n,s,n | -1.5-1tc |
| n,s,l | -2-2tc |
| n,n,s | 0.5-1tc |
| n,n,n | 0 |
| n,n,l | -0.5-1tc |
| n,l,s | 2-2tc |
| n,l,n | 1.5-1tc |
| n,l,l | 1-2tc |
| l,s,s | -1-4tc |
| l,s,n | -1.5-3tc |
| l,s,l | -2-3tc |
| l,n,s | 0.5-3tc |
| l,n,n | 0-2tc |
| l,n,l | -0.5-2tc |
| l,l,s | 2-3tc |
| l,l,n | 1.5-2tc |
| l,l,l | 1-2tc |
But you can drastically reduce the required calculations using backward induction/dynamic programming. Let denote the optimal value at time for price and “position” .
At time we have:
At time and , we have
At time and , we have
At time and state (the only relevant one at the start) we have